セルフホスト型のCIサーバーをローカルマシン1台で運用していると、ある日ふと不安になる瞬間があります。「このCI、本当に毎晩走っているんだろうか?」と。
ビルドやテストの成否は通知で分かります。しかし「実行されなかったこと」は、そもそも通知が飛んでこないので気づけません。ホストが落ちればcron自体が起動せず、nightlyワークフローは沈黙したまま消えていきます。これがセルフホストCI特有の **silent fail(静かな失敗)** です。
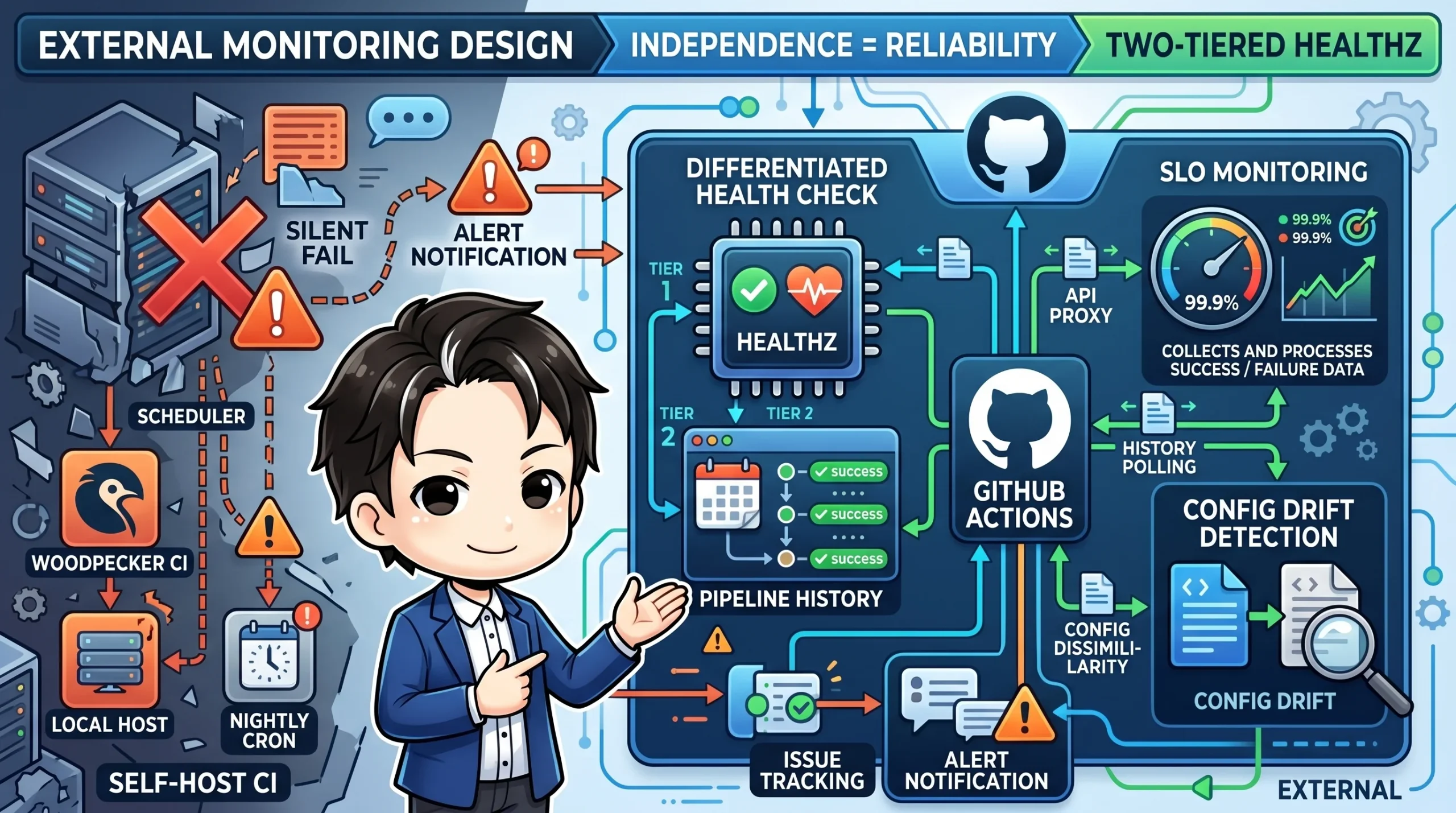
この記事では、セルフホストCI(Woodpecker CIを例にします)の運用において、**死活監視・SLO計測・config drift検出を「CIの外側」に外付けする設計**を扱います。CI基盤そのものの作り方やフェイルオーバー手順は別途まとめているので、ここでは触れません。あくまで「アプリ側・運用側から見て、CI基盤の健全性をどう観測し続けるか」という視点です。
## なぜ「監視対象と同じ場所」に監視を置いてはいけないのか
最初に陥りがちなのが、通知ジョブや死活チェックを **セルフホストCIの中に置いてしまう** 構成です。
これは循環依存になります。ホストが落ちた瞬間、CIが止まるだけでなく、その上に乗っている監視ジョブも通知ジョブも一緒に止まるからです。「CIが落ちているときに、そのCIを使って死活を確認しようとする」という、考えてみれば当たり前に破綻する構図です。共倒れする監視は、監視の名ばかりになります。
```mermaid
flowchart TB
subgraph host["ローカルホスト(落ちると全部止まる)"]
ci["セルフホストCI<br/>(Woodpecker)"]
bad["❌ 監視ジョブも<br/>ここに置くと共倒れ"]
end
subgraph gha["GitHub Actions(常時稼働マネージドrunner)"]
checker["死活監視 nightly"]
slo["月次SLO計測"]
drift["config drift検出"]
end
checker -->|"healthz + 履歴ポーリング"| ci
slo -->|"REST APIで成功率集計"| ci
drift -->|"設定値を照合"| ci
checker -->|"異常時"| issue["GitHub Issue自動起票<br/>+ Discord通知"]
```
解決策はシンプルで、**「常に生きているもの」を1つ前提として確保し、そこに監視ロジックを置く** ことです。GitHub Actionsの`ubuntu-latest`のようなマネージドrunnerは、自分のホストとは独立して動きます。監視対象がまるごと停止していても、checker自体は何事もなかったように走ります。この「独立した観測レイヤー」を持つことが設計の起点です。
## 死活監視は2段構えにする
監視を外に出したら、次は「何をもって生きていると判断するか」です。ここで`/api/healthz`のようなヘルスチェックエンドポイントだけに頼ると、片手落ちになります。
HTTP 200が返ってきても、それは「サーバープロセスは起動している」ことしか保証しません。**「サーバーは起きているが、cronが1本も走っていない」** という状態は健全に見えてしまいます。スケジューラだけ死んでいるケースは、healthzでは絶対に検出できません。
そこで2段構えにします。
1. **healthzチェック** — サーバーが応答するか
2. **パイプライン履歴チェック** — 直近の一定時間内に、cron起動のパイプラインが実際に成功しているか
2段目はREST APIでパイプライン履歴を取得し、lookback時間内の成功件数を数えます。
```bash
# 直近 LOOKBACK_HOURS 時間内の成功パイプライン数をカウント
CUTOFF_EPOCH=$(( $(date -u +%s) - LOOKBACK_HOURS * 3600 ))
CHECKED=$(jq 'length' /tmp/pipelines.json)
SUCCESS=$(jq --argjson cutoff "$CUTOFF_EPOCH" \
'[ .[]
| select(.status == "success")
| select((.finished_at // .updated_at // 0) >= $cutoff)
] | length' \
/tmp/pipelines.json)
```
地味ですが効くのが `.finished_at // .updated_at // 0` のフォールバックチェーンです。CIツールによっては実行中断などで`finished_at`がnullのまま残ることがあり、素朴に`.finished_at >= $cutoff`と書くとnull比較がfalseになってカウント漏れします。`updated_at`を代替にし、最後は数値`0`でガードしています。
### lookbackは検出SLAと揃える
`LOOKBACK_HOURS`の値は感覚で決めず、SLOの検出SLAと一致させます。「silent failを24時間以内に検出する」というSLOを置いているなら、lookbackも24時間です。これを12時間に縮めると、cronの実行帯(深夜〜早朝)から検査窓が外れてfalse positiveが頻発します。取得件数の上限も同様で、`?event=cron&limit=100`の`100`は「nightlyの本数 × 1日分 + PR/手動トリガーの余裕枠」から逆算した数字です。`limit`を小さくするとPRトリガーが重なった日に24時間分のcron結果を取りこぼします。**閾値はすべて根拠を数値で書く** のが、後から自分を救う習慣です。
### 通知が届かない前提で、Issueを必ず残す
異常を検出したら、Discord通知だけでなく **GitHub Issueを自動起票** します。理由は、ホストが落ちているとDiscord通知の経路自体が死んでいる可能性があるからです。Issue起票は`ubuntu-latest`上で完結するので、何があっても記録だけは残ります。
```yaml
- name: Open auto-detected issue on failure
if: failure() && (github.event_name == 'schedule')
env:
GH_TOKEN: ${{ secrets.GITHUB_TOKEN }}
run: |
payload=$(jq -nc \
--arg title "[health-check] CI silent fail 検出 on ${DATE_UTC}" \
--arg body "$BODY" \
--argjson labels '["nightly","auto-detected","infra","priority: 1-highest"]' \
'{title: $title, body: $body, labels: $labels}')
api POST /issues "$payload" >/dev/null
```
`github.event_name == 'schedule'`の条件が肝で、`workflow_dispatch`の手動テスト時にはIssueを起票しません。デバッグのたびにノイズIssueが量産されるのを防ぎます。
ちなみに、token未設定(初回セットアップ前)でも落ちないように、`WOODPECKER_TOKEN`が空ならパイプライン履歴チェックをskipしてhealthzのみで判定する **degraded mode** を入れておくと運用が楽です。`ok=skipped`という状態を明示的に定義し、後続のsummarizeステップは`ok=false`のときだけ`failure`に倒すようにします。「動かないよりdegradedで動く」ほうがトータルの運用コストは低くなります。
## 月次SLOを別CIから自動計測する
死活監視(落ちていないか)の次は、SLO計測(どれくらい健全に動いているか)です。月次のパイプライン成功率を定量化しておくと、「最近CIが不安定」という体感を数字で語れます。
ここでも循環依存に注意します。SLO計測スクリプトをCI本体の中に置くと、「SLOが悪化してCIが不安定な月ほど、計測自体も失敗する」という最悪のパターンになります。そこで、すでに死活監視が動いているGitHub Actionsの月次cronに、SLO集計ジョブを併設します。死活監視と同じ「監視は外」の思想で揃えるわけです。
集計で外せないのが **母数の設計** です。`running` / `pending` / `declined` / `killed` / `blocked` といった非終端ステータスは、SLOの分母から除外します。完了しなかったパイプラインをfailureとして数えると、「サーバーは動いていたが途中でkillされたジョブ」がSLOを不当に押し下げてしまうからです。SLOは「決着がついたパイプライン」だけで計算します。
実装面で踏みやすい地雷もいくつか共有します。
- **GH Actions Expressionを`run:`に直接展開しない**。`${{ steps.x.outputs.value }}`をシェルに直書きすると、値にメタ文字が混ざったときコマンドインジェクションになります。`env:`経由で環境変数として渡し、シェル内では`${TARGET_MONTH}`と参照します。
- **Issue重複チェックは完全一致で**。`gh issue list --search "in:title"`は部分一致なので、「YYYY-MM」を含むタイトル検索だと前月のIssueに誤マッチします。`jq`で`select(.title == "$title")`の完全一致フィルタを足して冪等性を確保します。
- **Discord embed fieldは1024文字上限**。workflowが多いと成功率一覧がすぐ超えます。1000文字で切って`"... (truncated)"`を付けないと、Discord APIが400を返します。
## config driftを夜間に検出する
意外と見落とされがちなのが、**CIツール自体の設定が知らぬ間にずれる** ことです。ビルドやテストの自動化はしていても、CIプラットフォームのセキュリティ設定(fork PRからのpipeline起動可否、可視性、trusted設定など)を定期照合しているチームは多くありません。
たとえばWebUIの「Allow Pull Requests」がいつの間にかONに変わると、fork PRからpipelineが起動できてシークレットに到達されるリスクが生まれます。設定を「ドキュメントに書いた」だけでは検証されません。**毎晩コードで照合する** 状態まで昇格させます。
```bash
# 期待値をコードに明示し、実値と照合する
drift_items=()
[ "$actual_allow_pr" != "$EXPECT_ALLOW_PR" ] && \
drift_items+=("Allow Pull Requests: actual=\`${actual_allow_pr}\` expected=\`${EXPECT_ALLOW_PR}\`")
[ "$actual_visibility" != "$EXPECT_VISIBILITY" ] && \
drift_items+=("Visibility: actual=\`${actual_visibility}\` expected=\`${EXPECT_VISIBILITY}\`")
if [ ${#drift_items[@]} -eq 0 ]; then
echo "[config-drift] no drift detected"
exit 0
fi
# 乖離あり → Discord通知 + Issue起票するが exit 0(pipeline は緑のまま)
```
`EXPECT_ALLOW_PR="false"`のような期待値を定数としてスクリプト内に宣言しておくと、**期待値そのものがコードレビューの対象** になります。ドキュメントより機械的に検証しやすくなります。
設計判断として重要なのは、**ドリフトを検出しても`exit 1`しない(CIを赤にしない)** ことです。設定ドリフトは緊急停止が必要なレベルではなく、翌朝に人間がtriageすれば十分です。CIを赤にすると当番が夜中に叩き起こされます。「CIが赤=今すぐ直す」という認知負荷の設計を守るため、ドリフトは黄信号(warning)に留めます。これはSLO違反の通知でも同じで、Woodpeckerの`skipped`ステータス(黄色表示)を使ってpipelineを緑に保ちつつDiscordにwarningを投げると、on-callアラートと開発CIをきれいに切り分けられます。
## 「重くなったらクラウドに戻す」を数値で判断する
最後に、セルフホストCIの運用で必ず来る問いです。「自社ホストに移したワークフロー、混んできたらGitHub Actionsに戻すべきか?」
これを体感で議論すると永遠にまとまりません。「なんとなく遅い」は人によって基準が違うからです。そこで、切り戻しトリガーを **先に定量化** しておきます。
- PR平均キュー待ち時間が **5分超を7日連続継続**
- PR平均wall-timeが **15分超を1週間継続**
- 同時並走起因のstep failureが **30日で3件以上**
3つ目の「同時並走起因」は、ログを`OCI runtime exec failed` / `cannot allocate memory` / `pool exhausted` / `executor busy`といったキーワードで検索して特定します。判定基準まで書いておくと再現性が出ます。
閾値を満たしたら、観測 → 起票 → 合意 → 実装 → 観察、という決まったフローを回すだけです。実装時の注意は1つだけ。**旧CIからの削除と新CIへの追加は同一PRでアトミックに** 行います。別PRに分けると、マージのタイミング次第で「PRゲートがどこにも存在しない期間」が生まれてしまうからです。
監視メトリクスがCIシステムをまたぐ点も意識しておきます。GitHub Actions側のbilling/job timingは`gh api`で取れますが、セルフホストCIのキュー時間はWebUIの手動確認しかできないことがあります。「どのメトリクスがどのシステムをカバーするか」を明示しておかないと、障害時に何を見ればいいか分からなくなります。
## 現役実装者の視点
正直に言うと、私が最初にこの仕組みを作ったのは、自宅で動かしているセルフホストCIが「動いているつもり」で実は数日止まっていた、という経験がきっかけでした。テストは通っているし通知も特に来ない、だから順調だと思い込んでいたのですが、ある日WebUIを開いたら直近のnightlyが軒並み実行されていませんでした。ホストが再起動した後にCIコンテナが上がりきっていなかっただけなのですが、「実行されなかったこと」には本当に気づけないのだと、そのとき肌で理解しました。
それ以来、監視ジョブだけは必ずCIの外、GitHub Actions側に置くようにしています。最初は「healthzが200なら大丈夫だろう」と思っていたのですが、スケジューラだけ死ぬパターンを踏んでから、パイプライン履歴のチェックを足しました。2段構えにしてからは、少なくとも「静かに止まっていた」という事故はなくなりました。
もう1つ効果が大きかったのが、切り戻し基準の数値化です。以前は「最近CI重いよね」という会話が出るたびに、戻すべきか戻さないべきかをふわっと議論して結論が出ず、結局放置していました。閾値を先に決めてしまってからは、障害時にも「今キュー待ちが何分で何日続いたか」を見るだけで判断できるようになり、迷いがほぼ消えました。監視も切り戻しも、結局は「未来の自分が迷わないための数値を、落ち着いているうちに置いておく」作業なのだと思っています。

セルフホスト型のCIサーバーをローカルマシン1台で運用していると、ある日ふと不安になる瞬間があります。「このCI、本当に毎晩走っているんだろうか?」と。
ビルドやテストの成否は通知で分かります。しかし「実行されなかったこと」は、そもそも通知が飛んでこないので気づけません。ホストが落ちればcron自体が起動せず、nightlyワークフローは沈黙したまま消えていきます。これがセルフホストCI特有の silent fail(静かな失敗) です。
この記事では、セルフホストCI(Woodpecker CIを例にします)の運用において、死活監視・SLO計測・config drift検出を「CIの外側」に外付けする設計を扱います。CI基盤そのものの作り方やフェイルオーバー手順は別途まとめているので、ここでは触れません。あくまで「アプリ側・運用側から見て、CI基盤の健全性をどう観測し続けるか」という視点です。
なぜ「監視対象と同じ場所」に監視を置いてはいけないのか
最初に陥りがちなのが、通知ジョブや死活チェックを セルフホストCIの中に置いてしまう 構成です。
これは循環依存になります。ホストが落ちた瞬間、CIが止まるだけでなく、その上に乗っている監視ジョブも通知ジョブも一緒に止まるからです。「CIが落ちているときに、そのCIを使って死活を確認しようとする」という、考えてみれば当たり前に破綻する構図です。共倒れする監視は、監視の名ばかりになります。
flowchart TB
subgraph host["ローカルホスト(落ちると全部止まる)"]
ci["セルフホストCI<br/>(Woodpecker)"]
bad["❌ 監視ジョブも<br/>ここに置くと共倒れ"]
end
subgraph gha["GitHub Actions(常時稼働マネージドrunner)"]
checker["死活監視 nightly"]
slo["月次SLO計測"]
drift["config drift検出"]
end
checker -->|"healthz + 履歴ポーリング"| ci
slo -->|"REST APIで成功率集計"| ci
drift -->|"設定値を照合"| ci
checker -->|"異常時"| issue["GitHub Issue自動起票<br/>+ Discord通知"]
解決策はシンプルで、「常に生きているもの」を1つ前提として確保し、そこに監視ロジックを置く ことです。GitHub Actionsのubuntu-latestのようなマネージドrunnerは、自分のホストとは独立して動きます。監視対象がまるごと停止していても、checker自体は何事もなかったように走ります。この「独立した観測レイヤー」を持つことが設計の起点です。
死活監視は2段構えにする
監視を外に出したら、次は「何をもって生きていると判断するか」です。ここで/api/healthzのようなヘルスチェックエンドポイントだけに頼ると、片手落ちになります。
HTTP 200が返ってきても、それは「サーバープロセスは起動している」ことしか保証しません。「サーバーは起きているが、cronが1本も走っていない」 という状態は健全に見えてしまいます。スケジューラだけ死んでいるケースは、healthzでは絶対に検出できません。
そこで2段構えにします。
- healthzチェック — サーバーが応答するか
- パイプライン履歴チェック — 直近の一定時間内に、cron起動のパイプラインが実際に成功しているか
2段目はREST APIでパイプライン履歴を取得し、lookback時間内の成功件数を数えます。
# 直近 LOOKBACK_HOURS 時間内の成功パイプライン数をカウント
CUTOFF_EPOCH=$(( $(date -u +%s) - LOOKBACK_HOURS * 3600 ))
CHECKED=$(jq 'length' /tmp/pipelines.json)
SUCCESS=$(jq --argjson cutoff "$CUTOFF_EPOCH" \
'[ .[]
| select(.status == "success")
| select((.finished_at // .updated_at // 0) >= $cutoff)
] | length' \
/tmp/pipelines.json)
地味ですが効くのが .finished_at // .updated_at // 0 のフォールバックチェーンです。CIツールによっては実行中断などでfinished_atがnullのまま残ることがあり、素朴に.finished_at >= $cutoffと書くとnull比較がfalseになってカウント漏れします。updated_atを代替にし、最後は数値0でガードしています。
lookbackは検出SLAと揃える
LOOKBACK_HOURSの値は感覚で決めず、SLOの検出SLAと一致させます。「silent failを24時間以内に検出する」というSLOを置いているなら、lookbackも24時間です。これを12時間に縮めると、cronの実行帯(深夜〜早朝)から検査窓が外れてfalse positiveが頻発します。取得件数の上限も同様で、?event=cron&limit=100の100は「nightlyの本数 × 1日分 + PR/手動トリガーの余裕枠」から逆算した数字です。limitを小さくするとPRトリガーが重なった日に24時間分のcron結果を取りこぼします。閾値はすべて根拠を数値で書く のが、後から自分を救う習慣です。
通知が届かない前提で、Issueを必ず残す
異常を検出したら、Discord通知だけでなく GitHub Issueを自動起票 します。理由は、ホストが落ちているとDiscord通知の経路自体が死んでいる可能性があるからです。Issue起票はubuntu-latest上で完結するので、何があっても記録だけは残ります。
- name: Open auto-detected issue on failure
if: failure() && (github.event_name == 'schedule')
env:
GH_TOKEN: ${{ secrets.GITHUB_TOKEN }}
run: |
payload=$(jq -nc \
--arg title "[health-check] CI silent fail 検出 on ${DATE_UTC}" \
--arg body "$BODY" \
--argjson labels '["nightly","auto-detected","infra","priority: 1-highest"]' \
'{title: $title, body: $body, labels: $labels}')
api POST /issues "$payload" >/dev/null
github.event_name == 'schedule'の条件が肝で、workflow_dispatchの手動テスト時にはIssueを起票しません。デバッグのたびにノイズIssueが量産されるのを防ぎます。
ちなみに、token未設定(初回セットアップ前)でも落ちないように、WOODPECKER_TOKENが空ならパイプライン履歴チェックをskipしてhealthzのみで判定する degraded mode を入れておくと運用が楽です。ok=skippedという状態を明示的に定義し、後続のsummarizeステップはok=falseのときだけfailureに倒すようにします。「動かないよりdegradedで動く」ほうがトータルの運用コストは低くなります。
月次SLOを別CIから自動計測する
死活監視(落ちていないか)の次は、SLO計測(どれくらい健全に動いているか)です。月次のパイプライン成功率を定量化しておくと、「最近CIが不安定」という体感を数字で語れます。
ここでも循環依存に注意します。SLO計測スクリプトをCI本体の中に置くと、「SLOが悪化してCIが不安定な月ほど、計測自体も失敗する」という最悪のパターンになります。そこで、すでに死活監視が動いているGitHub Actionsの月次cronに、SLO集計ジョブを併設します。死活監視と同じ「監視は外」の思想で揃えるわけです。
集計で外せないのが 母数の設計 です。running / pending / declined / killed / blocked といった非終端ステータスは、SLOの分母から除外します。完了しなかったパイプラインをfailureとして数えると、「サーバーは動いていたが途中でkillされたジョブ」がSLOを不当に押し下げてしまうからです。SLOは「決着がついたパイプライン」だけで計算します。
実装面で踏みやすい地雷もいくつか共有します。
- GH Actions Expressionを
run:に直接展開しない。${{ steps.x.outputs.value }}をシェルに直書きすると、値にメタ文字が混ざったときコマンドインジェクションになります。env:経由で環境変数として渡し、シェル内では${TARGET_MONTH}と参照します。
- Issue重複チェックは完全一致で。
gh issue list --search "in:title"は部分一致なので、「YYYY-MM」を含むタイトル検索だと前月のIssueに誤マッチします。jqでselect(.title == "$title")の完全一致フィルタを足して冪等性を確保します。
- Discord embed fieldは1024文字上限。workflowが多いと成功率一覧がすぐ超えます。1000文字で切って
"... (truncated)"を付けないと、Discord APIが400を返します。
config driftを夜間に検出する
意外と見落とされがちなのが、CIツール自体の設定が知らぬ間にずれる ことです。ビルドやテストの自動化はしていても、CIプラットフォームのセキュリティ設定(fork PRからのpipeline起動可否、可視性、trusted設定など)を定期照合しているチームは多くありません。
たとえばWebUIの「Allow Pull Requests」がいつの間にかONに変わると、fork PRからpipelineが起動できてシークレットに到達されるリスクが生まれます。設定を「ドキュメントに書いた」だけでは検証されません。毎晩コードで照合する 状態まで昇格させます。
# 期待値をコードに明示し、実値と照合する
drift_items=()
[ "$actual_allow_pr" != "$EXPECT_ALLOW_PR" ] && \
drift_items+=("Allow Pull Requests: actual=\`${actual_allow_pr}\` expected=\`${EXPECT_ALLOW_PR}\`")
[ "$actual_visibility" != "$EXPECT_VISIBILITY" ] && \
drift_items+=("Visibility: actual=\`${actual_visibility}\` expected=\`${EXPECT_VISIBILITY}\`")
if [ ${#drift_items[@]} -eq 0 ]; then
echo "[config-drift] no drift detected"
exit 0
fi
# 乖離あり → Discord通知 + Issue起票するが exit 0(pipeline は緑のまま)
EXPECT_ALLOW_PR="false"のような期待値を定数としてスクリプト内に宣言しておくと、期待値そのものがコードレビューの対象 になります。ドキュメントより機械的に検証しやすくなります。
設計判断として重要なのは、ドリフトを検出してもexit 1しない(CIを赤にしない) ことです。設定ドリフトは緊急停止が必要なレベルではなく、翌朝に人間がtriageすれば十分です。CIを赤にすると当番が夜中に叩き起こされます。「CIが赤=今すぐ直す」という認知負荷の設計を守るため、ドリフトは黄信号(warning)に留めます。これはSLO違反の通知でも同じで、Woodpeckerのskippedステータス(黄色表示)を使ってpipelineを緑に保ちつつDiscordにwarningを投げると、on-callアラートと開発CIをきれいに切り分けられます。
「重くなったらクラウドに戻す」を数値で判断する
最後に、セルフホストCIの運用で必ず来る問いです。「自社ホストに移したワークフロー、混んできたらGitHub Actionsに戻すべきか?」
これを体感で議論すると永遠にまとまりません。「なんとなく遅い」は人によって基準が違うからです。そこで、切り戻しトリガーを 先に定量化 しておきます。
- PR平均キュー待ち時間が 5分超を7日連続継続
- PR平均wall-timeが 15分超を1週間継続
- 同時並走起因のstep failureが 30日で3件以上
3つ目の「同時並走起因」は、ログをOCI runtime exec failed / cannot allocate memory / pool exhausted / executor busyといったキーワードで検索して特定します。判定基準まで書いておくと再現性が出ます。
閾値を満たしたら、観測 → 起票 → 合意 → 実装 → 観察、という決まったフローを回すだけです。実装時の注意は1つだけ。旧CIからの削除と新CIへの追加は同一PRでアトミックに 行います。別PRに分けると、マージのタイミング次第で「PRゲートがどこにも存在しない期間」が生まれてしまうからです。
監視メトリクスがCIシステムをまたぐ点も意識しておきます。GitHub Actions側のbilling/job timingはgh apiで取れますが、セルフホストCIのキュー時間はWebUIの手動確認しかできないことがあります。「どのメトリクスがどのシステムをカバーするか」を明示しておかないと、障害時に何を見ればいいか分からなくなります。
現役実装者の視点
正直に言うと、私が最初にこの仕組みを作ったのは、自宅で動かしているセルフホストCIが「動いているつもり」で実は数日止まっていた、という経験がきっかけでした。テストは通っているし通知も特に来ない、だから順調だと思い込んでいたのですが、ある日WebUIを開いたら直近のnightlyが軒並み実行されていませんでした。ホストが再起動した後にCIコンテナが上がりきっていなかっただけなのですが、「実行されなかったこと」には本当に気づけないのだと、そのとき肌で理解しました。
それ以来、監視ジョブだけは必ずCIの外、GitHub Actions側に置くようにしています。最初は「healthzが200なら大丈夫だろう」と思っていたのですが、スケジューラだけ死ぬパターンを踏んでから、パイプライン履歴のチェックを足しました。2段構えにしてからは、少なくとも「静かに止まっていた」という事故はなくなりました。
もう1つ効果が大きかったのが、切り戻し基準の数値化です。以前は「最近CI重いよね」という会話が出るたびに、戻すべきか戻さないべきかをふわっと議論して結論が出ず、結局放置していました。閾値を先に決めてしまってからは、障害時にも「今キュー待ちが何分で何日続いたか」を見るだけで判断できるようになり、迷いがほぼ消えました。監視も切り戻しも、結局は「未来の自分が迷わないための数値を、落ち着いているうちに置いておく」作業なのだと思っています。