## はじめに
CI が失敗したとき、Slack に流れる通知を見て、ログを開いて、原因を特定して、修正方針を考える——この一連の作業を AI エージェントが自動でやってくれたら、開発者の割り込みコストは大幅に減ります。
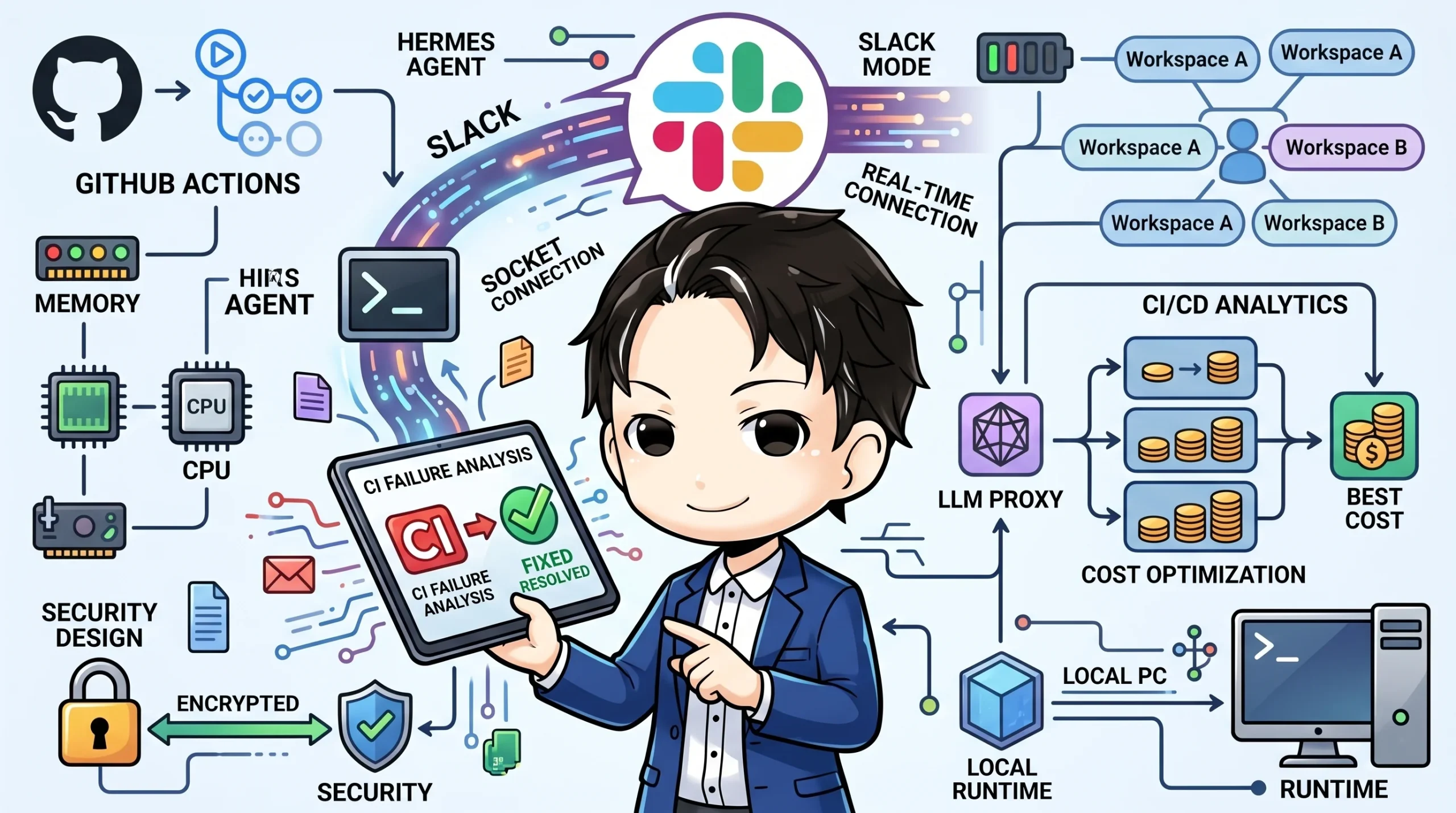
Nous Research の **Hermes Agent**(v0.12.x)と Slack の **Socket Mode** を組み合わせて、ローカル PC に常駐する AI 監視エージェントを構築しました。
公開 URL もサーバーも不要です。
WebSocket の**アウトバウンド接続のみ**で Slack にリアルタイム接続し、CI 失敗を検知して分析結果をスレッドに返します。
本記事では、ランタイム選定から LLM フォールバック設計、セキュリティ、運用上のポイントまでを紹介します。
## こんな人におすすめ
- CI 失敗の通知を受けてからログを読むまでの時間を短縮したい方
- Slack Bot を動かしたいが、公開 URL やサーバーを用意したくない方
- LLM の API コストを抑えながら AI エージェントを運用したい方
- AI エージェントのランタイム選定で比較検討中の方
## なぜ Hermes Agent を選んだのか
ランタイムの選定にあたり、Hermes Agent・OpenClaw・Claude Managed Agents の3候補を比較検証しました。
正直なところ、最初は Claude Managed Agents で十分だろうと考えていましたが、Slack Socket Mode のネイティブサポートという一点で Hermes Agent に決めました。
採用の決め手は以下の4点です。
- **Slack Socket Mode のネイティブサポート**: Bolt SDK for Python ベースで、WebSocket 接続を設定ファイル数行で実現できます。
ポーリング方式と比べてレイテンシが圧倒的に低く、リアルタイム監視に適しています
- **ローカル実行の軽量さ**: ホスト上で直接動かしても CPU・メモリ消費が小さく、開発用 PC で他の作業と並行して常駐させられます。
アイドル時のメモリ消費は約 200MB 程度です
- **永続メモリ**: 過去に解決した問題のパターンを記憶し、類似の CI 失敗を次回から自動で分析できます
- **マルチワークスペース対応**: 複数の Slack ワークスペースに同時接続でき、案件ごとにワークスペースが分かれている場合にも1つのエージェントで対応可能です
## アーキテクチャ: Socket Mode でインバウンド不要
従来の Slack Bot は Webhook のために公開 URL が必要でした。
Socket Mode はこの前提を覆します。
```mermaid
flowchart LR
A["GitHub Actions"] -->|"push event"| B["GitHub-Slack 連携"]
B -->|"/github subscribe"| C["Slack チャンネル"]
C -->|"Socket Mode<br/>WebSocket"| D["Hermes Agent<br/>(ローカル PC)"]
D -->|"分析結果"| C
style A fill:#e1f5ff,stroke:#0288d1,color:#000
style B fill:#fff3e0,stroke:#f57c00,color:#000
style C fill:#f3e5f5,stroke:#7b1fa2,color:#000
style D fill:#e8f5e9,stroke:#388e3c,color:#000
```
インバウンド接続がゼロのため、必要なものは以下だけです。
- ドメイン: 不要
- TLS 証明書: 不要
- リバースプロキシ: 不要
- ファイアウォール設定: 不要
自宅の PC やファイアウォール内の社内 PC から、そのまま Slack に常時接続できます。
## LiteLLM Proxy: 4段フォールバックでコスト最適化
AI エージェントの LLM バックエンドに、LiteLLM Proxy を挟んで4段のフォールバックチェーンを構築しました。
```yaml
model_list:
- model_name: "gpt-5.4-mini"
litellm_params:
model: codex/codex-mini-latest # L0: Codex(メイン)
- model_name: "gpt-5.4-mini"
litellm_params:
model: groq/llama-3.3-70b # L1: Groq(高速フォールバック)
- model_name: "gpt-5.4-mini"
litellm_params:
model: cerebras/llama-3.3-70b # L2: Cerebras(第2フォールバック)
- model_name: "gpt-5.4-mini"
litellm_params:
model: ollama/qwen2.5 # L3: ローカル Ollama(最終手段)
```
Hermes Agent からは `gpt-5.4-mini` という単一のモデル名で呼び出すだけです。
LiteLLM が L0 → L1 → L2 → L3 の順で自動フォールバックします。
**コストの内訳**: Codex と Groq の無料枠でほとんどの呼び出しをカバーし、それでも足りない場合は Cerebras、最終手段としてローカルの Ollama に落ちます。
実際に1ヶ月運用してみたところ、日常運用のコストはほぼゼロでした。
## CI 失敗分析スキルの仕組み
Hermes Agent の「スキル」として CI 失敗分析を実装しています。
トリガー条件は、Slack チャンネルに流れる GitHub-Slack 連携の CI 失敗通知です。
GitHub Actions の run が `failure` になると、GitHub-Slack 連携が通知を投稿し、Hermes がそれを検知します。
分析パイプラインは以下の流れです。
```mermaid
sequenceDiagram
participant S as Slack チャンネル
participant H as Hermes Agent
participant G as GitHub API
participant L as LLM (LiteLLM)
S->>H: CI 失敗通知を検知
H->>H: リポジトリ・run ID を抽出
H->>G: 失敗ステップのログ取得
G-->>H: ログデータ
H->>L: ログを渡して原因分析
L-->>H: 分析結果
H->>S: スレッドに分析結果を返信
```
1. **Slack メッセージからリポジトリ・run ID を抽出**
2. **GitHub API で失敗ステップのログを取得**
3. **LLM にログを渡して原因分析**(エラーメッセージ、スタックトレース、直近のコミットとの関連)
4. **分析結果を Slack スレッドに返信**(原因の要約、推奨修正アクション、関連するファイルパス)
分析結果は構造化されたフォーマットで返します。
```
🔴 CI Failure Analysis
Repository: org/repo-name
Branch: feature/xxx
Failed Step: Run tests
📋 Root Cause:
テストファイルで未定義の環境変数 DATABASE_URL を参照。
.env.test に追加が必要。
🔧 Suggested Fix:
1. .env.test に DATABASE_URL=postgresql://... を追加
2. CI workflow の env セクションにも同変数を追加
```
## Slack App Manifest で再現可能なセットアップ
Slack アプリの設定を JSON Manifest で管理しています。
手動での設定ミスを排除し、別ワークスペースへの展開も Manifest のインポートだけで完了します。
Hermes Agent の Slack 連携に必要な環境変数は4つです。
```bash
SLACK_BOT_TOKEN=xoxb-your-bot-token # Bot ユーザー認証
SLACK_APP_TOKEN=xapp-your-app-token # Socket Mode 接続用
SLACK_ALLOWED_USERS=U01ABC2DEF3 # 許可ユーザー(必須)
SLACK_HOME_CHANNEL=C01234567890 # 通知先チャンネル
```
Slack アプリ側で購読するイベントは以下です。
- `message.im` — DM の受信
- `message.channels` — パブリックチャンネルのメッセージ
- `app_mention` — @メンション検知
`channels:history` スコープが抜けていると、チャンネル内のメッセージを一切受信できません。
公式ドキュメントでもセットアップ時の最多ミスとして注意喚起されているポイントです。
## セキュリティ設計
### SLACK_ALLOWED_USERS は必須
`SLACK_ALLOWED_USERS` を設定しないと、Hermes はセキュリティ上すべてのメッセージを拒否します。
これは意図的な設計で、未設定のまま全メッセージに反応してしまうよりも安全です。
### シークレットの暗号化
API キーや認証情報は `age` 公開鍵暗号化で管理しています。
公開鍵1行で暗号化が完結し、復号には別途保管した秘密鍵が必要です。
CI に秘密鍵を置く必要がないため、Git に暗号化済みファイルをコミットしても安全です。
### GitHub Token のスコープ最小化
CI ログを取得するための GitHub Token には、`actions:read` と `contents:read` のみを付与しています。
書き込み権限は不要です。
## つまづいたポイント
### Socket Mode の再接続ハンドリング
WebSocket 接続は安定していますが、ネットワーク断やスリープからの復帰時に切断されることがあります。
Hermes は自動再接続を備えていますが、接続状態の監視ログを仕込んでおくと「いつの間にか落ちていた」を防げます。
実際、導入初期に2日間気づかず切断されていたことがありました。
ヘルスチェック用のエンドポイントを追加してからは、この問題は発生していません。
### SOUL.md でエージェントの人格を定義
Hermes Agent は `SOUL.md` というファイルでエージェントの振る舞いを定義します。
CI 失敗分析に特化した応答フォーマット、日本語での返信、degraded mode(LLM が応答しない場合)の通知テンプレートなどを記述しています。
### GitHub-Slack 連携のセットアップに5つの壁
GitHub と Slack の連携は、OAuth 認証 → org 承認 → チャンネル招待 → `/github subscribe` → 通知フィルタ設定と5段階のセットアップが必要です。
どこか1つでも抜けると通知が流れません。
個人的には、この5段階が一番時間を食いました。
オンボーディングドキュメントに全ステップを明記しておくことを強く推奨します。
## 得られた効果
導入から1ヶ月で、以下の改善が見られました。
- **CI 失敗の初動対応が平均15分→3分に短縮**: Hermes がログを読んで原因を要約してくれるので、開発者はスレッドを見るだけで修正方針がわかります
- **LLM コストほぼゼロ**: 4段フォールバックにより、無料枠の範囲で運用できています
- **永続メモリによる学習効果**: 同種の CI 失敗は2回目以降、より正確な分析結果を返すようになりました
- **セットアップの再現性**: Slack App Manifest + 環境変数4つで、別ワークスペースへの展開が30分で完了します
## まとめ
Hermes Agent と Slack Socket Mode の組み合わせは、「ローカル PC で動く AI 監視エージェント」という要件に対して非常に相性がよい構成でした。
- **Socket Mode** で公開 URL 不要のリアルタイム接続
- **LiteLLM Proxy** の4段フォールバックでコストほぼゼロの LLM 運用
- **CI 失敗分析スキル** で検知から原因分析・修正提案まで自動化
- **Slack App Manifest** で再現可能なセットアップ
サーバーレスや SaaS に頼らず、手元のマシンで AI エージェントを動かしたいケースでは、有力な選択肢になるはずです。

はじめに
CI が失敗したとき、Slack に流れる通知を見て、ログを開いて、原因を特定して、修正方針を考える——この一連の作業を AI エージェントが自動でやってくれたら、開発者の割り込みコストは大幅に減ります。
Nous Research の Hermes Agent(v0.12.x)と Slack の Socket Mode を組み合わせて、ローカル PC に常駐する AI 監視エージェントを構築しました。
公開 URL もサーバーも不要です。
WebSocket のアウトバウンド接続のみで Slack にリアルタイム接続し、CI 失敗を検知して分析結果をスレッドに返します。
本記事では、ランタイム選定から LLM フォールバック設計、セキュリティ、運用上のポイントまでを紹介します。
こんな人におすすめ
- CI 失敗の通知を受けてからログを読むまでの時間を短縮したい方
- Slack Bot を動かしたいが、公開 URL やサーバーを用意したくない方
- LLM の API コストを抑えながら AI エージェントを運用したい方
- AI エージェントのランタイム選定で比較検討中の方
なぜ Hermes Agent を選んだのか
ランタイムの選定にあたり、Hermes Agent・OpenClaw・Claude Managed Agents の3候補を比較検証しました。
正直なところ、最初は Claude Managed Agents で十分だろうと考えていましたが、Slack Socket Mode のネイティブサポートという一点で Hermes Agent に決めました。
採用の決め手は以下の4点です。
- Slack Socket Mode のネイティブサポート: Bolt SDK for Python ベースで、WebSocket 接続を設定ファイル数行で実現できます。
ポーリング方式と比べてレイテンシが圧倒的に低く、リアルタイム監視に適しています
- ローカル実行の軽量さ: ホスト上で直接動かしても CPU・メモリ消費が小さく、開発用 PC で他の作業と並行して常駐させられます。
アイドル時のメモリ消費は約 200MB 程度です
- 永続メモリ: 過去に解決した問題のパターンを記憶し、類似の CI 失敗を次回から自動で分析できます
- マルチワークスペース対応: 複数の Slack ワークスペースに同時接続でき、案件ごとにワークスペースが分かれている場合にも1つのエージェントで対応可能です
アーキテクチャ: Socket Mode でインバウンド不要
従来の Slack Bot は Webhook のために公開 URL が必要でした。
Socket Mode はこの前提を覆します。
flowchart LR
A["GitHub Actions"] -->|"push event"| B["GitHub-Slack 連携"]
B -->|"/github subscribe"| C["Slack チャンネル"]
C -->|"Socket Mode<br/>WebSocket"| D["Hermes Agent<br/>(ローカル PC)"]
D -->|"分析結果"| C
style A fill:#e1f5ff,stroke:#0288d1,color:#000
style B fill:#fff3e0,stroke:#f57c00,color:#000
style C fill:#f3e5f5,stroke:#7b1fa2,color:#000
style D fill:#e8f5e9,stroke:#388e3c,color:#000
インバウンド接続がゼロのため、必要なものは以下だけです。
- ドメイン: 不要
- TLS 証明書: 不要
- リバースプロキシ: 不要
- ファイアウォール設定: 不要
自宅の PC やファイアウォール内の社内 PC から、そのまま Slack に常時接続できます。
LiteLLM Proxy: 4段フォールバックでコスト最適化
AI エージェントの LLM バックエンドに、LiteLLM Proxy を挟んで4段のフォールバックチェーンを構築しました。
model_list:
- model_name: "gpt-5.4-mini"
litellm_params:
model: codex/codex-mini-latest # L0: Codex(メイン)
- model_name: "gpt-5.4-mini"
litellm_params:
model: groq/llama-3.3-70b # L1: Groq(高速フォールバック)
- model_name: "gpt-5.4-mini"
litellm_params:
model: cerebras/llama-3.3-70b # L2: Cerebras(第2フォールバック)
- model_name: "gpt-5.4-mini"
litellm_params:
model: ollama/qwen2.5 # L3: ローカル Ollama(最終手段)
Hermes Agent からは gpt-5.4-mini という単一のモデル名で呼び出すだけです。
LiteLLM が L0 → L1 → L2 → L3 の順で自動フォールバックします。
コストの内訳: Codex と Groq の無料枠でほとんどの呼び出しをカバーし、それでも足りない場合は Cerebras、最終手段としてローカルの Ollama に落ちます。
実際に1ヶ月運用してみたところ、日常運用のコストはほぼゼロでした。
CI 失敗分析スキルの仕組み
Hermes Agent の「スキル」として CI 失敗分析を実装しています。
トリガー条件は、Slack チャンネルに流れる GitHub-Slack 連携の CI 失敗通知です。
GitHub Actions の run が failure になると、GitHub-Slack 連携が通知を投稿し、Hermes がそれを検知します。
分析パイプラインは以下の流れです。
sequenceDiagram
participant S as Slack チャンネル
participant H as Hermes Agent
participant G as GitHub API
participant L as LLM (LiteLLM)
S->>H: CI 失敗通知を検知
H->>H: リポジトリ・run ID を抽出
H->>G: 失敗ステップのログ取得
G-->>H: ログデータ
H->>L: ログを渡して原因分析
L-->>H: 分析結果
H->>S: スレッドに分析結果を返信
- Slack メッセージからリポジトリ・run ID を抽出
- GitHub API で失敗ステップのログを取得
- LLM にログを渡して原因分析(エラーメッセージ、スタックトレース、直近のコミットとの関連)
- 分析結果を Slack スレッドに返信(原因の要約、推奨修正アクション、関連するファイルパス)
分析結果は構造化されたフォーマットで返します。
🔴 CI Failure Analysis
Repository: org/repo-name
Branch: feature/xxx
Failed Step: Run tests
📋 Root Cause:
テストファイルで未定義の環境変数 DATABASE_URL を参照。
.env.test に追加が必要。
🔧 Suggested Fix:
1. .env.test に DATABASE_URL=postgresql://... を追加
2. CI workflow の env セクションにも同変数を追加
Slack App Manifest で再現可能なセットアップ
Slack アプリの設定を JSON Manifest で管理しています。
手動での設定ミスを排除し、別ワークスペースへの展開も Manifest のインポートだけで完了します。
Hermes Agent の Slack 連携に必要な環境変数は4つです。
SLACK_BOT_TOKEN=xoxb-your-bot-token # Bot ユーザー認証
SLACK_APP_TOKEN=xapp-your-app-token # Socket Mode 接続用
SLACK_ALLOWED_USERS=U01ABC2DEF3 # 許可ユーザー(必須)
SLACK_HOME_CHANNEL=C01234567890 # 通知先チャンネル
Slack アプリ側で購読するイベントは以下です。
message.im — DM の受信message.channels — パブリックチャンネルのメッセージapp_mention — @メンション検知
channels:history スコープが抜けていると、チャンネル内のメッセージを一切受信できません。
公式ドキュメントでもセットアップ時の最多ミスとして注意喚起されているポイントです。
セキュリティ設計
SLACK_ALLOWED_USERS は必須
SLACK_ALLOWED_USERS を設定しないと、Hermes はセキュリティ上すべてのメッセージを拒否します。
これは意図的な設計で、未設定のまま全メッセージに反応してしまうよりも安全です。
シークレットの暗号化
API キーや認証情報は age 公開鍵暗号化で管理しています。
公開鍵1行で暗号化が完結し、復号には別途保管した秘密鍵が必要です。
CI に秘密鍵を置く必要がないため、Git に暗号化済みファイルをコミットしても安全です。
GitHub Token のスコープ最小化
CI ログを取得するための GitHub Token には、actions:read と contents:read のみを付与しています。
書き込み権限は不要です。
つまづいたポイント
Socket Mode の再接続ハンドリング
WebSocket 接続は安定していますが、ネットワーク断やスリープからの復帰時に切断されることがあります。
Hermes は自動再接続を備えていますが、接続状態の監視ログを仕込んでおくと「いつの間にか落ちていた」を防げます。
実際、導入初期に2日間気づかず切断されていたことがありました。
ヘルスチェック用のエンドポイントを追加してからは、この問題は発生していません。
Hermes Agent は SOUL.md というファイルでエージェントの振る舞いを定義します。
CI 失敗分析に特化した応答フォーマット、日本語での返信、degraded mode(LLM が応答しない場合)の通知テンプレートなどを記述しています。
GitHub-Slack 連携のセットアップに5つの壁
GitHub と Slack の連携は、OAuth 認証 → org 承認 → チャンネル招待 → /github subscribe → 通知フィルタ設定と5段階のセットアップが必要です。
どこか1つでも抜けると通知が流れません。
個人的には、この5段階が一番時間を食いました。
オンボーディングドキュメントに全ステップを明記しておくことを強く推奨します。
得られた効果
導入から1ヶ月で、以下の改善が見られました。
- CI 失敗の初動対応が平均15分→3分に短縮: Hermes がログを読んで原因を要約してくれるので、開発者はスレッドを見るだけで修正方針がわかります
- LLM コストほぼゼロ: 4段フォールバックにより、無料枠の範囲で運用できています
- 永続メモリによる学習効果: 同種の CI 失敗は2回目以降、より正確な分析結果を返すようになりました
- セットアップの再現性: Slack App Manifest + 環境変数4つで、別ワークスペースへの展開が30分で完了します
まとめ
Hermes Agent と Slack Socket Mode の組み合わせは、「ローカル PC で動く AI 監視エージェント」という要件に対して非常に相性がよい構成でした。
- Socket Mode で公開 URL 不要のリアルタイム接続
- LiteLLM Proxy の4段フォールバックでコストほぼゼロの LLM 運用
- CI 失敗分析スキル で検知から原因分析・修正提案まで自動化
- Slack App Manifest で再現可能なセットアップ
サーバーレスや SaaS に頼らず、手元のマシンで AI エージェントを動かしたいケースでは、有力な選択肢になるはずです。