## はじめに
コスト削減やプライバシー要件から、CI を self-hosted runner で動かす構成は珍しくありません。クラウドの従量課金を抑えられ、内部リソースにも直接アクセスできます。
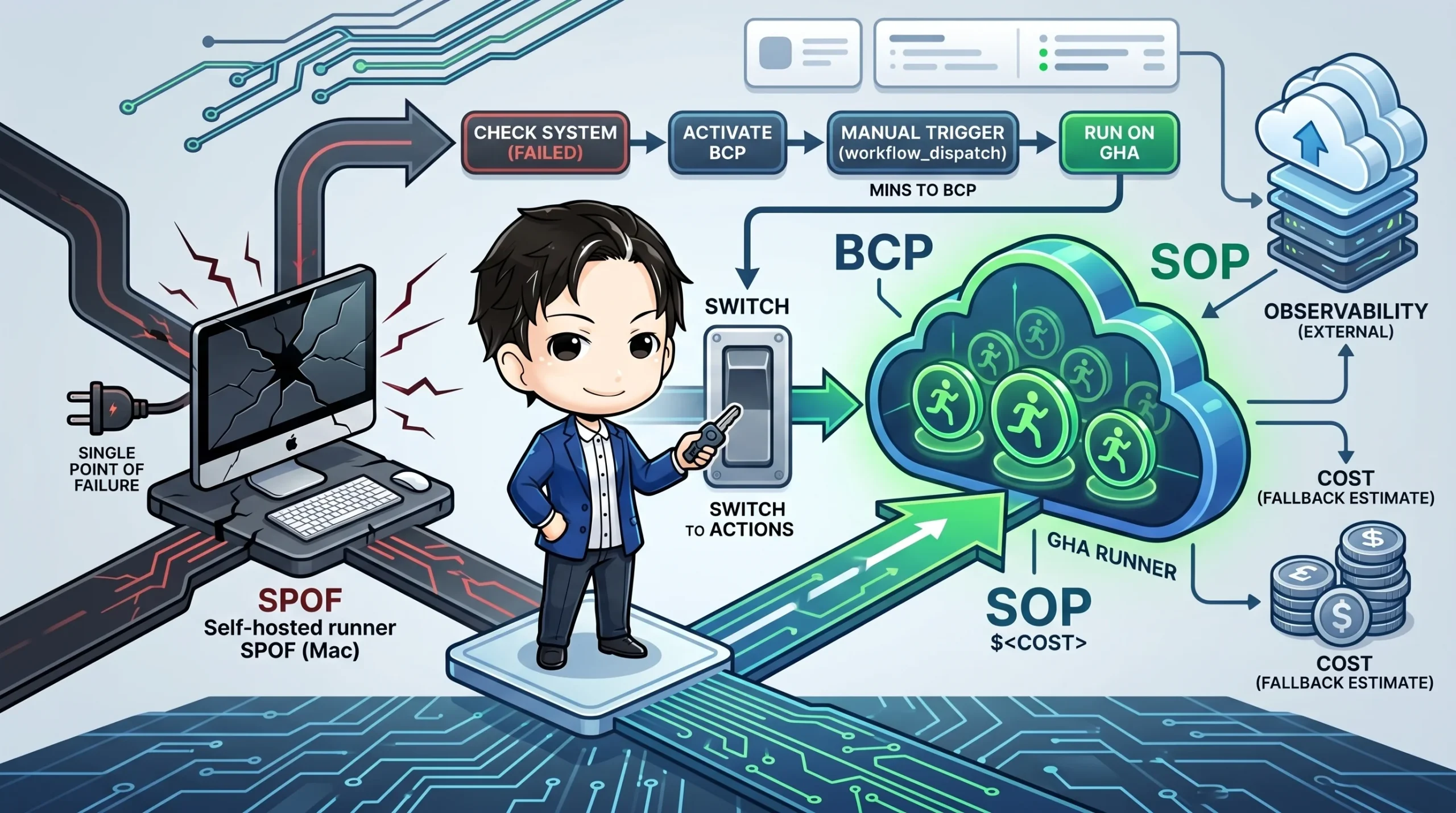
しかし、ここには見落とされがちな落とし穴があります。**自宅やオフィスの Mac 1 台で runner を動かしているなら、その 1 台が単一障害点(SPOF)になっている**ということです。電源断、再起動、ネットワーク断、Cloudflare Tunnel の停止——どれか 1 つで CI が全停止します。CI が止まれば、branch protection によって PR が永遠にマージできなくなり、デプロイも止まります。
本記事では、私が運用している Mac 1 台の CI 基盤を題材に、Mac 障害時に GitHub Actions(GHA-hosted runner)へ数分で切り替える BCP(事業継続計画)的な SOP を公開します。重い workflow を `workflow_dispatch` だけ残しておく平常時の備えから、障害の切り分け、branch protection を一時解除する切替手順、外部監視、コスト試算までを構造化しました。self-hosted runner やオンプレ CI を運用する SRE・CTO の方の参考になれば幸いです。
なお、本記事のホスト名・URL はすべて `ci.example.dev` 等のプレースホルダに置換しています。
## なぜ self-hosted runner は SPOF なのか
私の構成は、ざっくり次のようになっています。
- CI サーバ本体(Woodpecker 相当)が Mac 上の Docker で稼働
- 外部からの到達は Cloudflare Tunnel 経由(`https://ci.example.dev`)
- 一部の repo は GitHub Actions の native self-hosted runner(macOS)も使用
この構成は平常時こそ快適ですが、可用性の観点では脆いです。Mac の電源が落ちれば Docker も Tunnel も runner も全部一緒に死にます。CI に依存している全 repo の PR がマージ不能になり、デプロイの手段も失われます。クラウド CI なら基盤側が冗長化してくれている部分を、自前で抱え込んでいるわけです。
ここで重要なのは、**「冗長化を頑張る」のではなく「壊れたときに数分で逃げられる経路」を平常時に用意しておく**という発想です。Mac CI は普段のコストメリットを享受しつつ、障害時だけ GitHub Actions に避難する。これが BCP の現実解です。
## 平常時の備え:重い workflow を `workflow_dispatch` だけ残す
避難経路は、障害が起きてから作っても間に合いません。**平常時に GHA-hosted(`ubuntu-latest` / `macos-latest`)でも実行できる状態を残しておく**ことが SOP の核心です。
ポイントは、GHA の重い workflow(`test.yml` / `e2e.yml` / `deploy-cloudflare.yml` など)を **完全削除せず、`workflow_dispatch` トリガだけ残す**ことです。
```yaml
# .github/workflows/deploy-cloudflare.yml
name: deploy-cloudflare
on:
workflow_dispatch: # 緊急時のみ Actions タブ / gh CLI から手動 trigger
# push: ← 平常時は self-hosted で回すので削除(コメントアウトで残しておくと意図が伝わる)
# pull_request: ← 同上
# schedule: ← 同上
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
# ... 平常時と同じ手順 ...
```
ここでの判断基準は次の通りです。
- **重い workflow(test / e2e / deploy)**: 完全削除せず `workflow_dispatch` のみで温存する。通常トリガ(`push` / `pull_request` / `schedule`)は削除し、GHA 課金が走らないようにする
- **軽い workflow(lint / license-check / secret-scan 等)**: self-hosted 側で代替確認済みなら、GHA からは完全削除して良い
そして、**この避難手順を各アプリ repo の README に明記しておく**ことが大切です。障害時に「どの workflow を、どう叩けば代替できるか」をその場で調べる羽目になると、復旧時間が伸びます。
## 障害判別フロー:どこが死んだのかを切り分ける
「CI が動かない」状態にはいくつものパターンがあり、**切り分けの順序を間違えると誤った仮説で時間を浪費します**。最初に確認すべきは「そもそも自分側の障害なのか」です。
### Step 0: 上流(GitHub / Cloudflare)の障害確認——必ず最初に
- https://www.githubstatus.com/ : GitHub Actions / API / Webhooks のステータス
- https://www.cloudflarestatus.com/ : Cloudflare Tunnel のステータス
進行中の incident があれば原因はそれで確定です。**こちら側では直せないので復旧を待つ**のが正解。過去には、GitHub 側のトークン検証障害で `actions/checkout` が "Your account is suspended" を返したことがありました。アカウント停止とは無関係の上流障害で、慌てて自分の token を疑うと時間を溶かします。
### Step 1: Tunnel だけ停止(Mac は生きている)
ローカルからは到達できるのに、外部 URL 経由で到達できないパターンです。
```bash
# ローカルは OK / Tunnel 経由は NG
curl -sf http://localhost:9663/healthz && echo "local OK"
curl -sf https://ci.example.dev/healthz || echo "tunnel DOWN"
```
→ Tunnel を再起動し、`cloudflared` のログでエラーを確認します。Mac 本体は無事なので、GHA への切替までは不要なことが多いです。
### Step 2: Mac 死亡(リモートから到達不可)
```bash
# 別端末から external check
curl -sf https://ci.example.dev/healthz || echo "DOWN"
```
→ ローカルにも外部にも到達できない場合は Mac 本体の障害です。後述の「GHA dispatch 切替手順」へ進みます。
### Step 3: Docker Desktop だけ停止
```bash
docker info 2>&1 | head -3 # Mac は生きているが daemon に到達不可
```
→ Docker Desktop を手動起動し、CI スタックを再起動します。
### Step 4: native runner だけ Offline
```bash
launchctl list | grep actions.runner
```
→ runner プロセスのみの問題なら、launchd 経由で再起動します。
判別の優先順序は **Step 0 → 1 → 2 → 3 → 4**。上流確認を飛ばさないことが、無駄な調査を防ぐ最大のコツです。
## GHA dispatch 切替手順(Mac 完全障害時)
Mac 本体が死んだと判断したら、GitHub Actions への避難に入ります。
### Step 1: 影響範囲の特定
self-hosted runner(CI サーバ依存・native runner 依存)に紐づく repo を事前にリスト化しておきます。障害時にゼロから棚卸しすると遅いので、これも平常時のドキュメント作業です。
### Step 2: branch protection の required check を一時解除——ここが最大の罠
各 repo の `Settings > Branches > <main>` で、self-hosted 側のステータスチェック(例: `ci-success-summary`)を **required から一時的に外します**。
> **これを忘れると、CI が止まったまま PR が永遠にマージできない状態になります。** 「GHA で代替実行が green になっているのに、required に登録された self-hosted のチェック名が来ないのでマージできない」という詰みパターンです。GHA dispatch を叩く前に、必ず required check を外してください。
### Step 3: 重い workflow を手動 trigger
平常時に `workflow_dispatch` で残しておいた workflow を `gh` CLI で叩きます。
```bash
# デプロイを GHA で実行
gh workflow run -R my-org/my-app deploy-cloudflare.yml --ref main
gh run watch -R my-org/my-app
# e2e を GHA で実行
gh workflow run -R my-org/my-app e2e-critical-pr.yml --ref main
gh run watch -R my-org/my-app
```
### Step 4: 復旧後の手順
Mac 復旧後は、避難状態を確実に巻き戻します。
1. CI スタックを起動し、全サービスが healthy であることを確認
2. **Step 2 で外した required check を元に戻す**(戻し忘れると保護が効かないまま運用継続してしまう)
3. Discord / Slack で関係者に復旧を通知
4. インシデント記録(発生時刻・原因・対応・RTO)を残す
### 切替・復旧チェックリスト
```text
[ ] Step 0: githubstatus / cloudflarestatus に incident がないことを確認した
[ ] 影響を受ける repo を特定した
[ ] 各 repo の required check(self-hosted)を一時解除した
[ ] workflow_dispatch で重い workflow を trigger し green を確認した
[ ] (復旧後)CI スタックの healthy を確認した
[ ] (復旧後)required check を元に戻した
[ ] 関係者へ通知し、インシデントを記録した
```
## 外部可観測性:Mac に依存しない監視を持つ
Mac 障害の厄介な点は、**障害を検知する仕組みまで一緒に死ぬ**ことです。Mac 上のスクリプトで自分自身を監視しても、Mac が落ちたら通知も飛びません。だからこそ、**Mac から独立した第三者監視**が必須です。
- **UptimeRobot 等の外形監視**で `https://ci.example.dev/healthz` を 5 分間隔で監視し、ダウン時に Slack / Discord / メールへ通知する。これは Mac とは別基盤で動くので SPOF の外側にあります
- **GitHub Actions の billing usage 監視**で、GHA dispatch を多用した際の課金急増を検知する(後述のコストにも直結)
「監視対象が SPOF なら、監視主体は SPOF の外に置く」——当たり前のようでいて、自前 CI ではつい忘れがちな原則です。
## fallback 中の月コスト試算:復旧優先度の材料にする
GHA-hosted で代替したときの課金(Linux private repo は $0.008/min が目安)を、あらかじめ試算しておきます。これが **「いつまでに Mac を直すべきか」を判断する材料**になります。
- 移管済み repo の test/build を GHA 代替: 月 3,000 分相当 → 約 $24/月
- e2e を GHA 代替: 月 30 trigger × 30 分 → 約 $7/月
- nightly ビルドを GHA 代替: 月 30 trigger × 15 分 → 約 $4/月
合計でおおよそ **$35/月**、1 週間の fallback なら **$8 程度**です。この数字があると、「コスト的には 1〜2 週間 GHA で凌げるので、Mac の修理は焦らず正攻法でやる」「逆に月をまたぐなら冗長化投資を検討する」といった意思決定が、感覚ではなく金額ベースでできます。BCP において復旧を急ぐかどうかは、結局コストとリスクの天秤です。その天秤に乗せる数字を平常時に用意しておくこと自体が、SOP の重要な一部だと考えています。
## まとめ
- 自宅・オフィスの Mac 1 台 self-hosted runner は SPOF。冗長化より「数分で逃げる経路」を平常時に用意する
- 重い workflow は GHA から完全削除せず `workflow_dispatch` だけ残す。避難手順は repo の README に明記する
- 障害は「上流 → Tunnel → Mac → Docker → runner」の順で切り分ける
- GHA 切替時は **branch protection の required check の一時解除**を忘れない(忘れると PR が永遠にマージ不能)
- 監視主体は Mac の外(UptimeRobot 等)に置く
- fallback の月コストを試算し、復旧優先度の判断材料にする
## 現役実装者の視点
このSOPは机上で設計したものではなく、自宅の Mac 1 台で CI を回している中で実際にヒヤッとした経験から積み上げたものです。一番効いたのは、ある朝 Cloudflare Tunnel だけが落ちていて、ローカルからは CI が叩けるのに外部 URL からは到達できない、という状態に気づかず 30 分ほど別の原因を探してしまったときでした。あのとき Step 0 の上流確認と「localhost は OK か / Tunnel 経由は NG か」の二段チェックを習慣にしていなかったので、`actions/checkout` のトークンを疑ったり Docker を再起動したりと、見当違いのところを触って時間を溶かしました。切り分けの順序を文章にして手元に置いておくだけで、次に同じことが起きたときの復旧が体感で数倍速くなったのは、地味ですが大きかったです。
`workflow_dispatch` を残す設計に落ち着いたのも、最初から狙ったわけではありません。当初は「GHA の workflow は self-hosted に寄せたんだから消してしまえ」と一度全部消してしまい、いざ Mac が再起動から戻らない日に避難先がなくて青ざめた、というのが正直なところです。慌てて過去のコミットから workflow を復元して走らせましたが、トリガ設定や secrets の参照がずれていて一発では通りませんでした。それ以来、重い workflow は通常トリガだけ外して `workflow_dispatch` の口は残す、というのを徹底しています。branch protection の required check 解除も、最初の障害対応で見事に踏みました。GHA 側で代替実行が green になっているのに、required に登録した self-hosted のチェック名が来ないので PR がマージできない——「動いているのにマージできない」という、原因が分かるまで一番気持ちの悪い詰み方でした。
逆に、どこまで作り込むかの線引きには毎回悩みます。個人〜小規模の運用で CI を二重化して常時走らせるのは、コストも維持の手間も明らかに過剰です。私は「冗長化はしない、避難経路だけ用意する」と割り切りました。fallback の月コストを試算しているのもそのためで、「1〜2 週間なら GHA で凌げる金額だから Mac の修理は焦らず正攻法でやる」と金額で判断できると、障害時に変に慌てなくて済みます。BCP は壮大な仕組みよりも、こうした「外し忘れ・戻し忘れ・避難先の有無」をチェックリストで潰すほうが、現場では何倍も効くというのが今の実感です。

はじめに
コスト削減やプライバシー要件から、CI を self-hosted runner で動かす構成は珍しくありません。クラウドの従量課金を抑えられ、内部リソースにも直接アクセスできます。
しかし、ここには見落とされがちな落とし穴があります。自宅やオフィスの Mac 1 台で runner を動かしているなら、その 1 台が単一障害点(SPOF)になっているということです。電源断、再起動、ネットワーク断、Cloudflare Tunnel の停止——どれか 1 つで CI が全停止します。CI が止まれば、branch protection によって PR が永遠にマージできなくなり、デプロイも止まります。
本記事では、私が運用している Mac 1 台の CI 基盤を題材に、Mac 障害時に GitHub Actions(GHA-hosted runner)へ数分で切り替える BCP(事業継続計画)的な SOP を公開します。重い workflow を workflow_dispatch だけ残しておく平常時の備えから、障害の切り分け、branch protection を一時解除する切替手順、外部監視、コスト試算までを構造化しました。self-hosted runner やオンプレ CI を運用する SRE・CTO の方の参考になれば幸いです。
なお、本記事のホスト名・URL はすべて ci.example.dev 等のプレースホルダに置換しています。
なぜ self-hosted runner は SPOF なのか
私の構成は、ざっくり次のようになっています。
- CI サーバ本体(Woodpecker 相当)が Mac 上の Docker で稼働
- 外部からの到達は Cloudflare Tunnel 経由(
https://ci.example.dev)
- 一部の repo は GitHub Actions の native self-hosted runner(macOS)も使用
この構成は平常時こそ快適ですが、可用性の観点では脆いです。Mac の電源が落ちれば Docker も Tunnel も runner も全部一緒に死にます。CI に依存している全 repo の PR がマージ不能になり、デプロイの手段も失われます。クラウド CI なら基盤側が冗長化してくれている部分を、自前で抱え込んでいるわけです。
ここで重要なのは、「冗長化を頑張る」のではなく「壊れたときに数分で逃げられる経路」を平常時に用意しておくという発想です。Mac CI は普段のコストメリットを享受しつつ、障害時だけ GitHub Actions に避難する。これが BCP の現実解です。
平常時の備え:重い workflow を workflow_dispatch だけ残す
避難経路は、障害が起きてから作っても間に合いません。平常時に GHA-hosted(ubuntu-latest / macos-latest)でも実行できる状態を残しておくことが SOP の核心です。
ポイントは、GHA の重い workflow(test.yml / e2e.yml / deploy-cloudflare.yml など)を 完全削除せず、workflow_dispatch トリガだけ残すことです。
# .github/workflows/deploy-cloudflare.yml
name: deploy-cloudflare
on:
workflow_dispatch: # 緊急時のみ Actions タブ / gh CLI から手動 trigger
# push: ← 平常時は self-hosted で回すので削除(コメントアウトで残しておくと意図が伝わる)
# pull_request: ← 同上
# schedule: ← 同上
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
# ... 平常時と同じ手順 ...
ここでの判断基準は次の通りです。
- 重い workflow(test / e2e / deploy): 完全削除せず
workflow_dispatch のみで温存する。通常トリガ(push / pull_request / schedule)は削除し、GHA 課金が走らないようにする
- 軽い workflow(lint / license-check / secret-scan 等): self-hosted 側で代替確認済みなら、GHA からは完全削除して良い
そして、この避難手順を各アプリ repo の README に明記しておくことが大切です。障害時に「どの workflow を、どう叩けば代替できるか」をその場で調べる羽目になると、復旧時間が伸びます。
障害判別フロー:どこが死んだのかを切り分ける
「CI が動かない」状態にはいくつものパターンがあり、切り分けの順序を間違えると誤った仮説で時間を浪費します。最初に確認すべきは「そもそも自分側の障害なのか」です。
Step 0: 上流(GitHub / Cloudflare)の障害確認——必ず最初に
進行中の incident があれば原因はそれで確定です。こちら側では直せないので復旧を待つのが正解。過去には、GitHub 側のトークン検証障害で actions/checkout が "Your account is suspended" を返したことがありました。アカウント停止とは無関係の上流障害で、慌てて自分の token を疑うと時間を溶かします。
Step 1: Tunnel だけ停止(Mac は生きている)
ローカルからは到達できるのに、外部 URL 経由で到達できないパターンです。
# ローカルは OK / Tunnel 経由は NG
curl -sf http://localhost:9663/healthz && echo "local OK"
curl -sf https://ci.example.dev/healthz || echo "tunnel DOWN"
→ Tunnel を再起動し、cloudflared のログでエラーを確認します。Mac 本体は無事なので、GHA への切替までは不要なことが多いです。
Step 2: Mac 死亡(リモートから到達不可)
# 別端末から external check
curl -sf https://ci.example.dev/healthz || echo "DOWN"
→ ローカルにも外部にも到達できない場合は Mac 本体の障害です。後述の「GHA dispatch 切替手順」へ進みます。
Step 3: Docker Desktop だけ停止
docker info 2>&1 | head -3 # Mac は生きているが daemon に到達不可
→ Docker Desktop を手動起動し、CI スタックを再起動します。
Step 4: native runner だけ Offline
launchctl list | grep actions.runner
→ runner プロセスのみの問題なら、launchd 経由で再起動します。
判別の優先順序は Step 0 → 1 → 2 → 3 → 4。上流確認を飛ばさないことが、無駄な調査を防ぐ最大のコツです。
GHA dispatch 切替手順(Mac 完全障害時)
Mac 本体が死んだと判断したら、GitHub Actions への避難に入ります。
Step 1: 影響範囲の特定
self-hosted runner(CI サーバ依存・native runner 依存)に紐づく repo を事前にリスト化しておきます。障害時にゼロから棚卸しすると遅いので、これも平常時のドキュメント作業です。
Step 2: branch protection の required check を一時解除——ここが最大の罠
各 repo の Settings > Branches > <main> で、self-hosted 側のステータスチェック(例: ci-success-summary)を required から一時的に外します。
これを忘れると、CI が止まったまま PR が永遠にマージできない状態になります。 「GHA で代替実行が green になっているのに、required に登録された self-hosted のチェック名が来ないのでマージできない」という詰みパターンです。GHA dispatch を叩く前に、必ず required check を外してください。
Step 3: 重い workflow を手動 trigger
平常時に workflow_dispatch で残しておいた workflow を gh CLI で叩きます。
# デプロイを GHA で実行
gh workflow run -R my-org/my-app deploy-cloudflare.yml --ref main
gh run watch -R my-org/my-app
# e2e を GHA で実行
gh workflow run -R my-org/my-app e2e-critical-pr.yml --ref main
gh run watch -R my-org/my-app
Step 4: 復旧後の手順
Mac 復旧後は、避難状態を確実に巻き戻します。
- CI スタックを起動し、全サービスが healthy であることを確認
- Step 2 で外した required check を元に戻す(戻し忘れると保護が効かないまま運用継続してしまう)
- Discord / Slack で関係者に復旧を通知
- インシデント記録(発生時刻・原因・対応・RTO)を残す
切替・復旧チェックリスト
[ ] Step 0: githubstatus / cloudflarestatus に incident がないことを確認した
[ ] 影響を受ける repo を特定した
[ ] 各 repo の required check(self-hosted)を一時解除した
[ ] workflow_dispatch で重い workflow を trigger し green を確認した
[ ] (復旧後)CI スタックの healthy を確認した
[ ] (復旧後)required check を元に戻した
[ ] 関係者へ通知し、インシデントを記録した
外部可観測性:Mac に依存しない監視を持つ
Mac 障害の厄介な点は、障害を検知する仕組みまで一緒に死ぬことです。Mac 上のスクリプトで自分自身を監視しても、Mac が落ちたら通知も飛びません。だからこそ、Mac から独立した第三者監視が必須です。
- UptimeRobot 等の外形監視で
https://ci.example.dev/healthz を 5 分間隔で監視し、ダウン時に Slack / Discord / メールへ通知する。これは Mac とは別基盤で動くので SPOF の外側にあります
- GitHub Actions の billing usage 監視で、GHA dispatch を多用した際の課金急増を検知する(後述のコストにも直結)
「監視対象が SPOF なら、監視主体は SPOF の外に置く」——当たり前のようでいて、自前 CI ではつい忘れがちな原則です。
fallback 中の月コスト試算:復旧優先度の材料にする
GHA-hosted で代替したときの課金(Linux private repo は $0.008/min が目安)を、あらかじめ試算しておきます。これが 「いつまでに Mac を直すべきか」を判断する材料になります。
- 移管済み repo の test/build を GHA 代替: 月 3,000 分相当 → 約 $24/月
- e2e を GHA 代替: 月 30 trigger × 30 分 → 約 $7/月
- nightly ビルドを GHA 代替: 月 30 trigger × 15 分 → 約 $4/月
合計でおおよそ $35/月、1 週間の fallback なら $8 程度です。この数字があると、「コスト的には 1〜2 週間 GHA で凌げるので、Mac の修理は焦らず正攻法でやる」「逆に月をまたぐなら冗長化投資を検討する」といった意思決定が、感覚ではなく金額ベースでできます。BCP において復旧を急ぐかどうかは、結局コストとリスクの天秤です。その天秤に乗せる数字を平常時に用意しておくこと自体が、SOP の重要な一部だと考えています。
まとめ
- 自宅・オフィスの Mac 1 台 self-hosted runner は SPOF。冗長化より「数分で逃げる経路」を平常時に用意する
- 重い workflow は GHA から完全削除せず
workflow_dispatch だけ残す。避難手順は repo の README に明記する
- 障害は「上流 → Tunnel → Mac → Docker → runner」の順で切り分ける
- GHA 切替時は branch protection の required check の一時解除を忘れない(忘れると PR が永遠にマージ不能)
- 監視主体は Mac の外(UptimeRobot 等)に置く
- fallback の月コストを試算し、復旧優先度の判断材料にする
現役実装者の視点
このSOPは机上で設計したものではなく、自宅の Mac 1 台で CI を回している中で実際にヒヤッとした経験から積み上げたものです。一番効いたのは、ある朝 Cloudflare Tunnel だけが落ちていて、ローカルからは CI が叩けるのに外部 URL からは到達できない、という状態に気づかず 30 分ほど別の原因を探してしまったときでした。あのとき Step 0 の上流確認と「localhost は OK か / Tunnel 経由は NG か」の二段チェックを習慣にしていなかったので、actions/checkout のトークンを疑ったり Docker を再起動したりと、見当違いのところを触って時間を溶かしました。切り分けの順序を文章にして手元に置いておくだけで、次に同じことが起きたときの復旧が体感で数倍速くなったのは、地味ですが大きかったです。
workflow_dispatch を残す設計に落ち着いたのも、最初から狙ったわけではありません。当初は「GHA の workflow は self-hosted に寄せたんだから消してしまえ」と一度全部消してしまい、いざ Mac が再起動から戻らない日に避難先がなくて青ざめた、というのが正直なところです。慌てて過去のコミットから workflow を復元して走らせましたが、トリガ設定や secrets の参照がずれていて一発では通りませんでした。それ以来、重い workflow は通常トリガだけ外して workflow_dispatch の口は残す、というのを徹底しています。branch protection の required check 解除も、最初の障害対応で見事に踏みました。GHA 側で代替実行が green になっているのに、required に登録した self-hosted のチェック名が来ないので PR がマージできない——「動いているのにマージできない」という、原因が分かるまで一番気持ちの悪い詰み方でした。
逆に、どこまで作り込むかの線引きには毎回悩みます。個人〜小規模の運用で CI を二重化して常時走らせるのは、コストも維持の手間も明らかに過剰です。私は「冗長化はしない、避難経路だけ用意する」と割り切りました。fallback の月コストを試算しているのもそのためで、「1〜2 週間なら GHA で凌げる金額だから Mac の修理は焦らず正攻法でやる」と金額で判断できると、障害時に変に慌てなくて済みます。BCP は壮大な仕組みよりも、こうした「外し忘れ・戻し忘れ・避難先の有無」をチェックリストで潰すほうが、現場では何倍も効くというのが今の実感です。