Cloudflare Workers 上で動かしているあるSaaSに、有料プランのユーザーへ週次サマリーをメールで届ける機能を実装しました。「Workers にはメール送信のバインディングがあるんだから、それを使えばいいだろう」と軽く考えていたのですが、ここに最初の落とし穴があります。
この記事では、その罠を起点に、Resend + Cloudflare Queues + DB ステートマシンで「二重配信しない冪等な週次配信基盤」を組み上げるまでの全体像を、実際の実装コードとともに解説します。
罠: send_email バインディングはエンドユーザー宛に使えない
Cloudflare Workers には Email Routing と連動した send_email バインディングがあります。wrangler で設定すれば Worker から await env.SEND_EMAIL.send(message) のようにメールを送れる、便利な仕組みに見えます。
ですが、これには重大な制約があります。send_email バインディングは Email Routing で「検証済み宛先(verified destination)」として登録したアドレスにしか送信できません。 つまり、任意のエンドユーザーのメールアドレスには送れないのです。
これは「自分宛の運用通知を Worker から飛ばす」用途には十分ですが、不特定多数のユーザーへ届けるトランザクショナルメール配信には根本的に向きません。エンドユーザー全員のアドレスを事前に Email Routing へ登録するのは現実的ではないからです。
ということで、外部のトランザクショナルメールプロバイダを使う構成に切り替えます。今回は Resend を採用しました。Workers から HTTP API 経由で叩くだけなので、SDK の Node.js 依存に悩まされることもありません。
// Resend を HTTP API 経由で叩く(Workers の fetch だけで完結)
async function sendViaResend(env: Env, mail: OutgoingMail): Promise<SendResult> {
const res = await fetch('https://api.resend.com/emails', {
method: 'POST',
headers: {
Authorization: `Bearer ${env.RESEND_API_KEY}`,
'Content-Type': 'application/json',
},
body: JSON.stringify({
from: env.MAIL_FROM,
to: [mail.to],
subject: mail.subject,
html: mail.html,
headers: mail.headers, // List-Unsubscribe など
tags: { variant: mail.variant }, // 後述の A/B 計測用
}),
})
if (!res.ok) {
return { status: 'failed', error: `resend ${res.status}` }
}
const body = await res.json<{ id: string }>()
return { status: 'sent', messageId: body.id }
}
SDK を Worker バンドルに持ち込まず、Web 標準の fetch だけで送信できるのが Workers との相性の良さです。
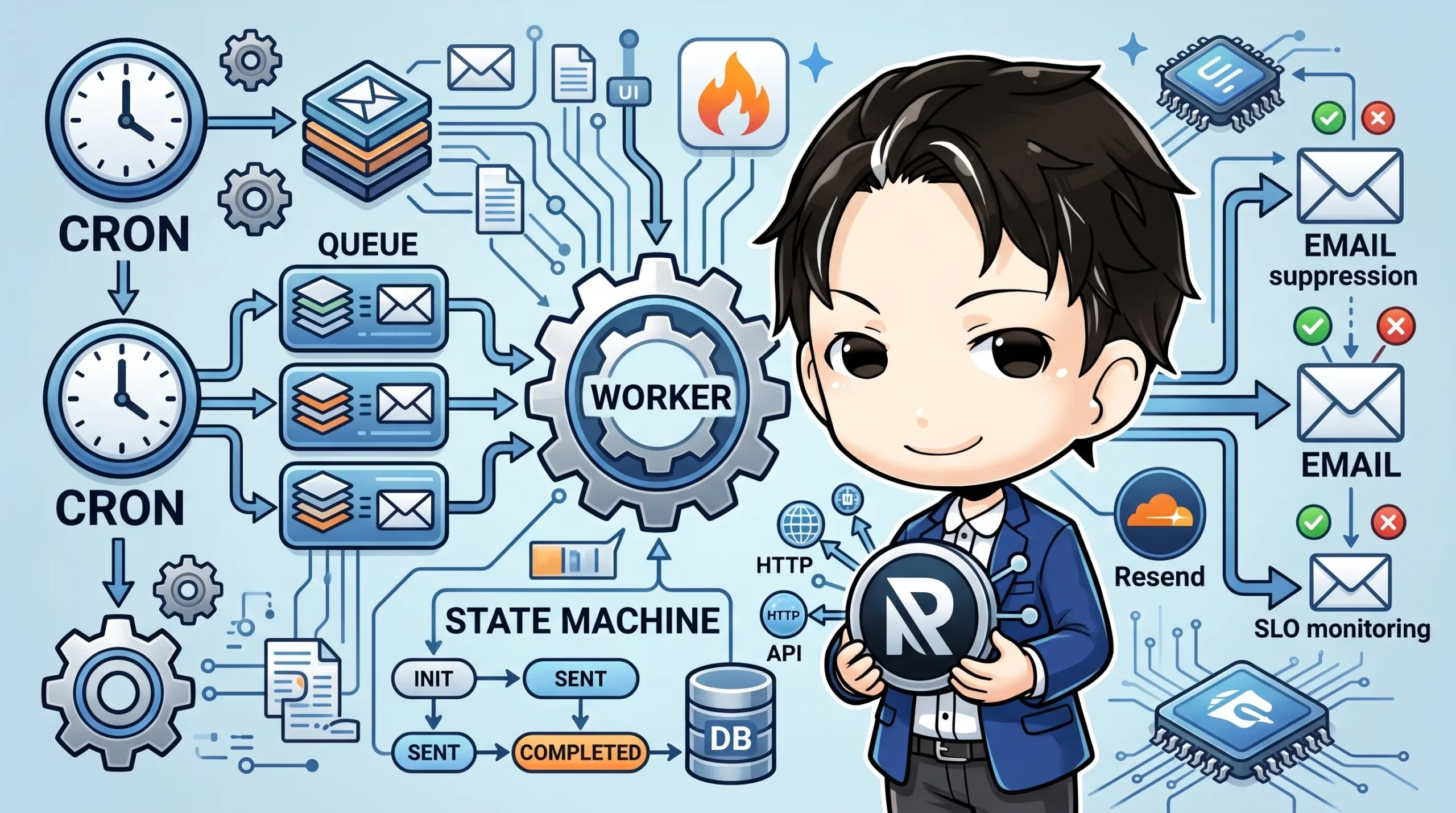
全体構成: Cron → Queue → Handler の3段
配信基盤は次の3段で構成します。
flowchart LR
Cron["Cron Trigger\n(週次 kick)"] -->|"INSERT delivery\n+ enqueue"| Queue["Cloudflare Queue"]
Queue --> Handler["Queue Handler\n(送信処理)"]
Handler -->|"HTTP API"| Resend["Resend"]
Resend -.->|"bounce / complaint"| Webhook["Webhook Endpoint"]
Webhook -->|"suppression"| DB[("DB\nステートマシン")]
Handler --> DB
Cron --> DB
ポイントは「Cron が直接メールを送らない」ことです。Cron は配信レコードを DB に作って Queue に積むだけ。実際の送信は Queue Handler が担います。これにより、送信のリトライ・スロットリング・エラー隔離を Queues に任せられます。
そしてこの3段構成で最も神経を使うのが冪等性です。Cron が二重発火しても、Queues がリトライしても、同じユーザーに同じ週のメールを2通送ってはいけません。
冪等性は DB ステートマシンで担保する
冪等性をアプリ側のロック機構ではなく、DB のアトミックな操作だけで担保しました。鍵は2つの仕掛けです。
仕掛け1: 複合 UNIQUE 制約 + ON CONFLICT DO NOTHING
配信レコードに (ユーザーID, 対象ID, ISO週) の複合 UNIQUE 制約を張り、Cron は INSERT ... ON CONFLICT DO NOTHING RETURNING id で投入します。
// Cron ハンドラ: 新規行が作れたときだけ enqueue する
const isoWeek = getJstIsoWeek(new Date(scheduledTime))
const deliveryRow = await firstRow<{ id: number }>(
env.DB,
`INSERT INTO weekly_report_deliveries
(subscriber_user_id, target_user_id, iso_week, scheduled_for)
VALUES (?, ?, ?, now())
ON CONFLICT (subscriber_user_id, target_user_id, iso_week) DO NOTHING
RETURNING id`,
subscriberUserId, targetUserId, isoWeek,
)
// RETURNING が空 = 既に同じ週の行がある → enqueue をスキップ
if (deliveryRow) {
messages.push({ body: { type: 'weekly-report', deliveryId: deliveryRow.id } })
}
ON CONFLICT DO NOTHING のとき RETURNING は行を返しません。つまり「行を新規作成できたときだけ Queue に積む」が1クエリで書けます。Cron が二重発火しても、手動でリトライしても、Queue にメッセージが重複して入りません。
仕掛け2: 排他的 UPDATE で Queue Handler の二重実行を止める
Cloudflare Queues は「Worker が ack() を呼ばずにタイムアウトした」場合などにメッセージをリトライします。つまり Handler 側でも同一メッセージが2回処理されうるので、ここでもガードが必要です。
採用したのは processing_started_at を使った排他的 UPDATE です。
// Queue Handler: 「まだ処理が始まっていない行」を掴めたときだけ続行する
const delivery = await firstRow<DeliveryRow>(
db,
`UPDATE weekly_report_deliveries
SET processing_started_at = now(), updated_at = now()
WHERE id = ? AND processing_started_at IS NULL
RETURNING id, subscriber_user_id, target_user_id, iso_week`,
msg.deliveryId,
)
if (!delivery) {
// 0 行更新 = 既に誰かが処理中/処理済み → リトライの二重実行をここで止める
console.log(`[queue] skipped (already processed) deliveryId=${msg.deliveryId}`)
return
}
WHERE ... AND processing_started_at IS NULL の条件付き UPDATE は DB がアトミックに評価するので、アプリ側でロックを持つ必要がありません。更新が0行なら「もう誰かが掴んだ」と判断して即 return します。
ステートマシンとして見ると、各レコードはチャネル別にこう遷移します。
stateDiagram-v2
[*] --> pending: Cron が INSERT
pending --> processing: 排他 UPDATE で掴む
processing --> sent: Resend 送信成功
processing --> failed: 送信エラー
processing --> skipped: 権限失効 / 宛先なし
failed --> sent: リトライ成功
テーブル定義
ステータスはチャネル(メール / Push / 監査ログ)ごとに分けて持ちます。CHECK 制約付きの文字列 enum にしておくと、CREATE TYPE が不要で、TypeScript 側の union 型と同期させやすくなります。
create table if not exists weekly_report_deliveries (
id bigint generated always as identity primary key,
subscriber_user_id uuid not null,
target_user_id uuid not null,
iso_week text not null,
scheduled_for timestamptz not null,
processing_started_at timestamptz, -- 排他制御用
email_status text not null default 'pending'
check (email_status in ('pending', 'skipped', 'sent', 'failed')),
push_status text not null default 'pending'
check (push_status in ('pending', 'skipped', 'sent', 'failed', 'no_subscription')),
last_error text
);
-- 複合 UNIQUE: Cron 二重発火を DB 制約で封じる
create unique index uq_deliveries_subscriber_target_week
on weekly_report_deliveries (subscriber_user_id, target_user_id, iso_week);
-- pending 行だけを対象にした部分インデックス(詰まり検出を速くする)
create index idx_deliveries_pending on weekly_report_deliveries (created_at desc)
where email_status = 'pending' or push_status = 'pending';
設計上のもう一つの勘所として、送信権限(entitlement)の再チェックは Cron 投入時ではなく Handler 処理時に行います。 Cron が積んでから Handler が処理するまでの間に課金が取り消される可能性があるためです。処理時点で DB に問い合わせ直すことで「送る瞬間の権限」を保証できます。
また、Queue のペイロードには PII を載せません。 メールアドレスを直接メッセージに埋めず deliveryId だけを渡し、Handler 側で DB から引き直します。Queue のログやデッドレターに個人情報が残るリスクを避けるためです。
bounce / complaint の suppression
トランザクショナルメールを運用していると、必ずバウンス(宛先不達)や苦情(迷惑メール報告)が発生します。これを放置すると Resend 側の送信レピュテーションが下がり、正常な宛先にも届きにくくなります。
そこで Resend の email.bounced / email.complained イベントを受け取る Webhook エンドポイントを用意し、該当ユーザーの定期配信を自動で無効化(suppression)します。
Webhook の署名検証は、外部 SDK を持ち込まず Web Crypto API だけで HMAC-SHA256 を自前実装しました。
function timingSafeEqual(left: Uint8Array, right: Uint8Array): boolean {
if (left.length !== right.length) return false
let diff = 0
for (let i = 0; i < left.length; i++) diff |= left[i] ^ right[i]
return diff === 0 // 短絡 return しない=タイミングで長さを漏らさない
}
Webhook も冪等であるべきです。同一イベントが複数回届くことがあるので、受信ログテーブルの主キーをベンダー提供のイベントID(svix-id)にして、配信レコードと同じ ON CONFLICT DO NOTHING RETURNING で初回判定します。
INSERT INTO webhook_events (event_id, event_type, email_id, recipient_email, payload_json, received_at)
VALUES (?, ?, ?, ?, ?::jsonb, ?)
ON CONFLICT (event_id) DO NOTHING
RETURNING event_id -- 行が戻れば初回、空なら重複
無効化はカスケードで行います。1人の受信者が複数の対象に紐づくケースがあるので、INSERT ... SELECT ... ON CONFLICT DO UPDATE で関連する通知設定をまとめて OFF にします。なお、デプロイ中のメンテナンスモードでも Webhook は受け取り続ける必要があるため、メンテナンスの bypass パスに追加しておくのも忘れずに。Stripe など決済 Webhook の定石と同じ考え方です。
配信ログ閲覧(admin)と SLO 監視(nightly)
「配信が静かに壊れていても誰も気づかない」のが定期配信の盲点です。これを2つの仕組みで補います。
admin の配信ログ閲覧ページでは、(ユーザーID, 対象ID, ISO週) ごとの配信ステータスを、複数ステータス軸でフィルタしながら確認できます。DB が返す文字列カラムは as const ユニオン型に正規化しておき、不正値が入ってもフロントがクラッシュしないようにします。
export const DELIVERY_EMAIL_STATUSES =
['pending', 'skipped', 'sent', 'failed'] as const
export type DeliveryEmailStatus = (typeof DELIVERY_EMAIL_STATUSES)[number]
nightly の SLO 監視では、失敗率を集計してアラートします。ここで効くのが「決着済み母数」の考え方です。skipped(送信対象外)や pending(未処理)を分母に入れると、対象外レコードが多いプランでは失敗率が希薄化して監視が機能しません。母数は sent + failed のみにします。
const emailDecidedTotal = emailSent + emailFailed
const failedRatePercent =
emailDecidedTotal === 0 ? 0 : (emailFailed / emailDecidedTotal) * 100
さらに、失敗率とは別軸で「processing_started_at が NULL のまま1時間以上経過した行」を stuck として検出します。Queue Handler が一度も掴まずに死んでいるケースは failed には現れないので、独立した監視が要ります。
運用上の工夫として、SLO 違反は CI の「失敗(赤)」ではなく「warning(黄)」として通知し、パイプラインは緑のまま保ちます。CI 本体の障害と、業務上の「要確認」を切り分けるためです。
なお、メール本文には RFC 8058 準拠の1クリック配信停止(HMAC 署名付き List-Unsubscribe エンドポイント)も組み込んでいますが、これは設計の論点が多いので別記事に切り出します。本記事では「環境変数の有無をフィーチャーフラグにして、シークレット未設定なら従来の設定画面 URL にフォールバックする段階的有効化を採った」とだけ触れておきます。同様に、件名や CTA を変える A/B バリアントも feature flag で制御していますが、その際は露出記録を「送信成功後」にのみ発火させるのがポイントです。skipped / failed を露出にカウントすると open/click rate の分母が汚れてしまうためです。
現役実装者の視点
正直に書くと、最初は send_email バインディングで普通にユーザー宛に送れると思い込んでいました。wrangler の設定もすんなり通って、自分のアドレス宛のテストも飛んだので「いけた」と思ったんです。ところが別のアドレスに送ろうとした瞬間に弾かれて、ドキュメントを読み直してようやく「検証済み宛先にしか送れない」ことに気づきました。運用通知用の機能を、エンドユーザー向け配信に流用しようとしていたわけです。ここで Resend に切り替えたのは早い段階の判断としては正解でした。
冪等性をどう担保するかは、かなり遠回りしました。最初はアプリ側で「送信済みかどうか」をチェックしてから送る、という素朴な実装にしていたのですが、Cron の二重発火と Queue のリトライが重なると、チェックと送信の間にすり抜けが起きます。結局、判定と状態遷移を DB の1クエリにまとめてアトミックにやらせる形に落ち着きました。ON CONFLICT DO NOTHING RETURNING で「積むかどうか」、条件付き UPDATE で「処理するかどうか」を DB に決めさせる。アプリ側にロックを持たない方が、Workers のようにインスタンスが分散・短命な環境では圧倒的に堅牢です。
もう一つ実感したのは、配信基盤は「送る部分」より「壊れていることに気づく部分」の方が後から効いてくるということです。admin の閲覧ページと nightly の SLO 監視は、機能としては地味で後回しにしがちなのですが、これがないと bounce が静かに積み上がって、ある日突然到達率が落ちる、という事故になります。失敗率の分母から skipped を抜く、stuck を別軸で見る、といった細かい設計判断は、どれも「実際に運用で困った」あとに入れたものです。最初から完璧に設計するのは難しいので、ログと監視を早めに置いて、壊れ方を観察できる状態を作っておくのが結局いちばん早かったように思います。