## はじめに
Claude Code の API コストを抑えたい。
あるいは、機密性の高いコードを外部に送信せずに AI エージェントを使いたい。
こうした動機から、Claude Code をローカル LLM で動かせないか検証しました。
**LiteLLM** を API プロキシとして挟み、**Ollama** 上の **Qwen 3** に接続する構成です。
結論から言うと、Qwen 3 系モデルでは Claude Code との互換性が不足しており、実用には至りませんでした。
しかし、環境構築の過程で得られた知見——LiteLLM のモデルマッピング、Ollama の API 構成、Claude Code のシステムプロンプトが求める要件——は、今後のローカル LLM 活用に役立つはずです。
本記事では、構成の全体像からエラーの原因と対処法、今後の展望までを解説します。
## こんな人におすすめ
- Claude Code の API コストを削減したい方
- オフラインや閉じたネットワーク環境で Claude Code を使いたい方
- LiteLLM や Ollama を使ったローカル LLM 環境の構築に興味がある方
- ローカル LLM と AI エージェントの互換性を検証したい方
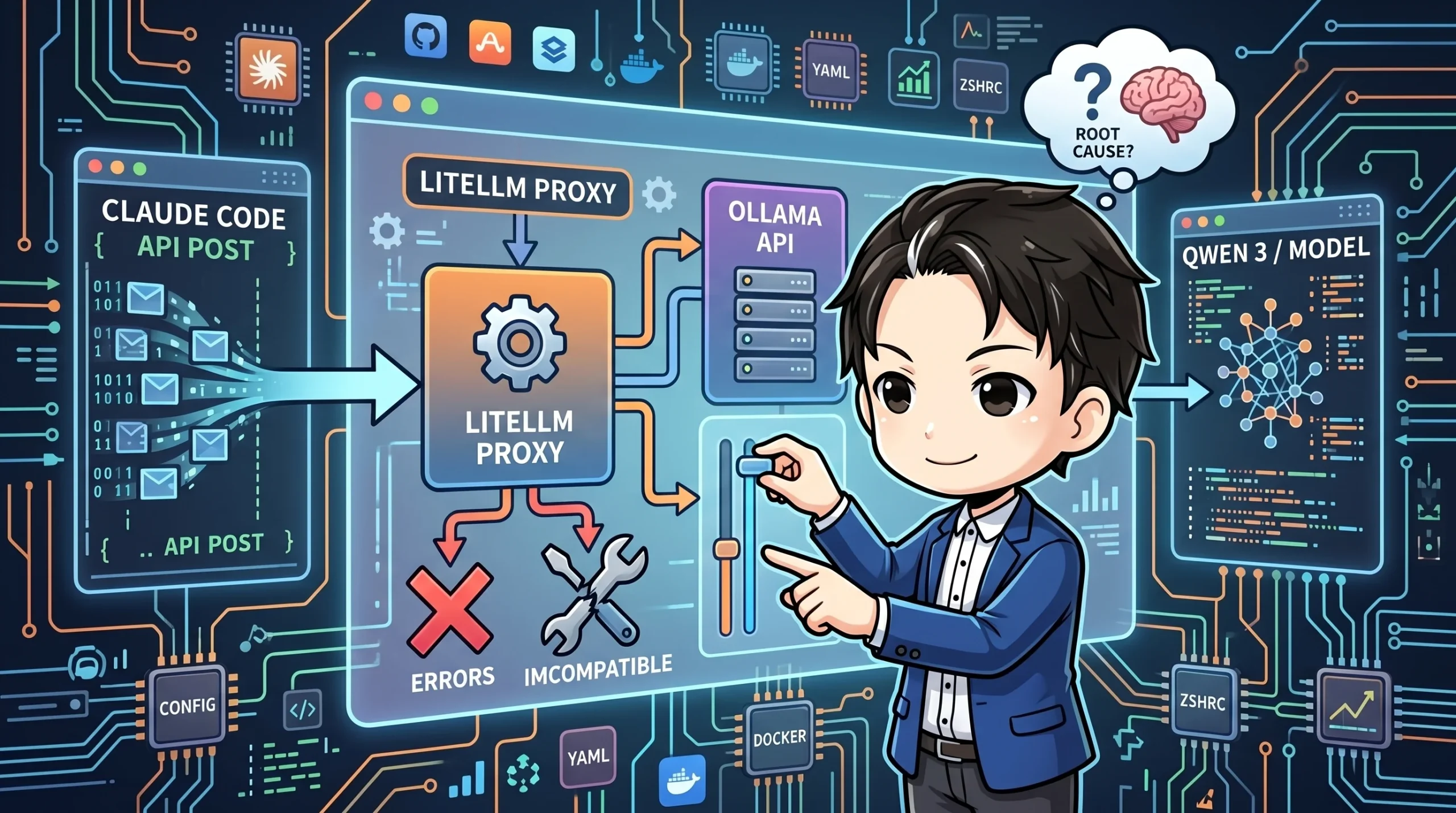
## アーキテクチャ: 3 層構成で API を変換
Claude Code は Anthropic API 形式でリクエストを送信します。
これをローカル LLM に中継するため、LiteLLM をプロキシ層として挟む 3 層構成にしました。
```mermaid
flowchart LR
A["Claude Code"] -->|"Anthropic API<br/>localhost:4000"| B["LiteLLM Proxy<br/>(Docker)"]
B -->|"ollama_chat 形式<br/>localhost:11434"| C["Ollama"]
C --> D["Qwen 3 / Qwen 3 Coder"]
style A fill:#e1f5ff,stroke:#0288d1,color:#000
style B fill:#fff3e0,stroke:#f57c00,color:#000
style C fill:#f3e5f5,stroke:#7b1fa2,color:#000
style D fill:#e8f5e9,stroke:#388e3c,color:#000
```
リクエストの流れは以下のとおりです。
1. Claude Code が `localhost:4000`(LiteLLM)に Anthropic API 形式で POST
2. LiteLLM がリクエストを Ollama 形式に変換し、`localhost:11434` に中継
3. Ollama が Qwen 3 モデルで推論を実行
4. レスポンスが逆方向に変換されて Claude Code に返る
Claude Code 側からは、通常の Anthropic API を呼んでいるように見えます。
## 環境構築: Docker Compose + zshrc 設定
### LiteLLM の設定ファイル
LiteLLM の `config.yaml` で、Claude のモデル名を Qwen にマッピングします。
```yaml
model_list:
- model_name: "claude-sonnet-4-20250514"
litellm_params:
model: "ollama_chat/qwen3"
api_base: "http://host.docker.internal:11434"
drop_params: true
additional_drop_params:
- "thinking"
- "thinking_budget_tokens"
litellm_settings:
drop_params: true
```
`drop_params: true` がポイントです。
Claude Code は `thinking` や `thinking_budget_tokens` など Anthropic 固有のパラメータを送信しますが、Ollama はこれらを理解できません。
LiteLLM に不要パラメータを自動除去させることで、リクエストを通します。
### Docker Compose
```yaml
services:
litellm:
image: ghcr.io/berriai/litellm:main-latest
ports:
- "4000:4000"
volumes:
- ./config.yaml:/app/config.yaml
command: --config /app/config.yaml
```
`host.docker.internal` で Docker コンテナから Mac 上の Ollama に接続します。
### シェル関数で切り替え
`.zshrc` に `--qwen` フラグを追加して、通常の Claude Code と切り替えられるようにしました。
```bash
function claude() {
if [[ "$1" == "--qwen" ]]; then
shift
ANTHROPIC_BASE_URL="http://localhost:4000" \
MAX_THINKING_TOKENS=0 \
command claude "$@"
else
command claude "$@"
fi
}
```
`claude --qwen` で起動すると、リクエスト先が LiteLLM に切り替わります。
`MAX_THINKING_TOKENS=0` で Anthropic 固有の thinking 機能を無効化しています。
## 遭遇した 4 つのエラーと対処法
検証過程で遭遇したエラーを、発生順に紹介します。
合計で 2〜3 時間ほど費やしました。
### エラー 1: モデル名不一致(400 Bad Request)
**症状**: Claude Code が送信するモデル名が `config.yaml` の定義と一致せず 400 エラー。
**原因**: Claude Code が実際に送信するモデル名は、CLI のバージョンや設定によって変わることがあります。
**対処**: LiteLLM のログ(`docker compose logs -f`)から実際のモデル名を確認し、`config.yaml` を修正しました。
最初にこの原因を特定するだけで 30 分ほどかかりました。
LiteLLM のログを有効にしておくのが鉄則です。
### エラー 2: "does not support thinking"(500 Internal Server Error)
**症状**: `thinking` パラメータがサポートされていないというエラー。
**原因**: Qwen 3 が Anthropic の `thinking` パラメータを理解できません。
**対処**: `MAX_THINKING_TOKENS=0` 環境変数で Claude Code 側から thinking を無効化しました。
加えて、LiteLLM の `additional_drop_params` にも `thinking` と `thinking_budget_tokens` を指定して二重に対策しています。
### エラー 3: "Operation not allowed" レスポンス
**症状**: LLM からの応答が `Operation not allowed` というテキスト。
HTTP レベルではエラーではなく、正常なレスポンスとして返ってきます。
**原因**: Qwen 3 が Claude Code のシステムプロンプトを読み、その中のセキュリティ制約を「自分への指示」と誤認して動作を拒否していました。
Claude Code のシステムプロンプトには、ファイル操作やコマンド実行に関する詳細な権限制御が含まれています。
Qwen 3 はこれを「やってはいけないこと」と解釈してしまったようです。
**対処**: これはモデルの指示追従能力の問題であり、設定レベルでは回避できませんでした。
### エラー 4: JSON 形式の応答
**症状**: `{"response": "4"}` のような JSON 形式で応答が返る。
**原因**: Claude Code のシステムプロンプトに含まれる出力フォーマット指示に、Qwen 3 が過剰に従っていました。
本来はツール呼び出しの応答形式ですが、通常の会話応答まで JSON で返してしまいます。
**対処**: これもモデル側の問題であり、設定では回避できませんでした。
## なぜ動かなかったのか: 根本原因の分析
4 つのエラーのうち、最初の 2 つは設定で回避できました。
しかし後半の 2 つ——システムプロンプトの誤解釈と JSON 応答——はモデルの能力に起因する問題です。
Claude Code のシステムプロンプトは非常に複雑で、以下の要素を含みます。
- ファイル操作・コマンド実行の権限制御
- ツール呼び出しの応答フォーマット指定
- セキュリティ制約と禁止事項
- コンテキスト管理のルール
これらを正確に解釈して、適切に応答するには、高度な指示追従能力が必要です。
Qwen 3 系モデルは汎用的な性能は高いのですが、Claude Code が求めるレベルの指示追従には達していませんでした。
## 得られた知見
検証は「失敗」でしたが、以下の知見は今後のローカル LLM 活用に役立ちます。
- **LiteLLM の `drop_params` は強力**: プロバイダ固有のパラメータを自動除去でき、異なる API 間の橋渡しに使えます
- **Ollama + Docker Compose の組み合わせは安定**: 環境構築自体は `config.yaml` 1 ファイルで完結します。LLM プロキシとしての基盤は実用レベルです
- **システムプロンプトの複雑さがボトルネック**: AI エージェントツールをローカル LLM で動かす際の最大の壁は、モデルの基本性能ではなく、システムプロンプトへの追従能力でした
- **`claude --qwen` のようなフラグ切り替え**: シェル関数での環境変数切り替えは、他のツールでも応用できるパターンです
## よくある質問
### Q: 他のローカル LLM なら動きますか?
Qwen 3 で動かなかった主因は指示追従能力です。
Llama 3.3 70B や DeepSeek Coder V2 など、より大きなパラメータ数のモデルであれば改善する可能性はあります。
ただし、Claude Code のシステムプロンプトの複雑さを考えると、現時点では厳しいかもしれません。
### Q: LiteLLM の設定は難しいですか?
Docker と Ollama がインストール済みであれば、`config.yaml` を書くだけなので比較的簡単です。
つまづきやすいのはモデル名のマッピングで、LiteLLM のログを見ながら調整する必要があります。
### Q: コスト削減の他の方法はありますか?
Claude Code には `--model` オプションで軽量モデルを指定する方法があります。
また、Anthropic の API キャッシュ機能を活用すれば、同じプロンプトの再送信コストを削減できます。
完全にローカルで動かすよりも、まずはこちらの方が現実的です。
## まとめ
Claude Code を LiteLLM + Ollama + Qwen 3 でローカル動作させる検証を行いましたが、システムプロンプトの互換性が壁となり実用には至りませんでした。
- **環境構築自体は簡単**: Docker Compose + `config.yaml` で LiteLLM プロキシが立ち上がります
- **設定で回避できるエラーと、できないエラーがある**: `drop_params` で Anthropic 固有パラメータは除去できますが、モデルの指示追従能力は設定では補えません
- **AI エージェントのローカル LLM 化は「次の段階」**: モデル性能の向上と、エージェントツール側のプロキシ対応が進めば、実現の可能性は高まります
「失敗した検証」ですが、LiteLLM の活用パターンや Ollama との連携方法など、他のプロジェクトでも再利用できる知見が得られました。
ローカル LLM の進化は速いので、半年後には状況が変わっているかもしれません。

はじめに
Claude Code の API コストを抑えたい。
あるいは、機密性の高いコードを外部に送信せずに AI エージェントを使いたい。
こうした動機から、Claude Code をローカル LLM で動かせないか検証しました。
LiteLLM を API プロキシとして挟み、Ollama 上の Qwen 3 に接続する構成です。
結論から言うと、Qwen 3 系モデルでは Claude Code との互換性が不足しており、実用には至りませんでした。
しかし、環境構築の過程で得られた知見——LiteLLM のモデルマッピング、Ollama の API 構成、Claude Code のシステムプロンプトが求める要件——は、今後のローカル LLM 活用に役立つはずです。
本記事では、構成の全体像からエラーの原因と対処法、今後の展望までを解説します。
こんな人におすすめ
- Claude Code の API コストを削減したい方
- オフラインや閉じたネットワーク環境で Claude Code を使いたい方
- LiteLLM や Ollama を使ったローカル LLM 環境の構築に興味がある方
- ローカル LLM と AI エージェントの互換性を検証したい方
アーキテクチャ: 3 層構成で API を変換
Claude Code は Anthropic API 形式でリクエストを送信します。
これをローカル LLM に中継するため、LiteLLM をプロキシ層として挟む 3 層構成にしました。
flowchart LR
A["Claude Code"] -->|"Anthropic API<br/>localhost:4000"| B["LiteLLM Proxy<br/>(Docker)"]
B -->|"ollama_chat 形式<br/>localhost:11434"| C["Ollama"]
C --> D["Qwen 3 / Qwen 3 Coder"]
style A fill:#e1f5ff,stroke:#0288d1,color:#000
style B fill:#fff3e0,stroke:#f57c00,color:#000
style C fill:#f3e5f5,stroke:#7b1fa2,color:#000
style D fill:#e8f5e9,stroke:#388e3c,color:#000
リクエストの流れは以下のとおりです。
- Claude Code が
localhost:4000(LiteLLM)に Anthropic API 形式で POST
- LiteLLM がリクエストを Ollama 形式に変換し、
localhost:11434 に中継
- Ollama が Qwen 3 モデルで推論を実行
- レスポンスが逆方向に変換されて Claude Code に返る
Claude Code 側からは、通常の Anthropic API を呼んでいるように見えます。
環境構築: Docker Compose + zshrc 設定
LiteLLM の設定ファイル
LiteLLM の config.yaml で、Claude のモデル名を Qwen にマッピングします。
model_list:
- model_name: "claude-sonnet-4-20250514"
litellm_params:
model: "ollama_chat/qwen3"
api_base: "http://host.docker.internal:11434"
drop_params: true
additional_drop_params:
- "thinking"
- "thinking_budget_tokens"
litellm_settings:
drop_params: true
drop_params: true がポイントです。
Claude Code は thinking や thinking_budget_tokens など Anthropic 固有のパラメータを送信しますが、Ollama はこれらを理解できません。
LiteLLM に不要パラメータを自動除去させることで、リクエストを通します。
Docker Compose
services:
litellm:
image: ghcr.io/berriai/litellm:main-latest
ports:
- "4000:4000"
volumes:
- ./config.yaml:/app/config.yaml
command: --config /app/config.yaml
host.docker.internal で Docker コンテナから Mac 上の Ollama に接続します。
シェル関数で切り替え
.zshrc に --qwen フラグを追加して、通常の Claude Code と切り替えられるようにしました。
function claude() {
if [[ "$1" == "--qwen" ]]; then
shift
ANTHROPIC_BASE_URL="http://localhost:4000" \
MAX_THINKING_TOKENS=0 \
command claude "$@"
else
command claude "$@"
fi
}
claude --qwen で起動すると、リクエスト先が LiteLLM に切り替わります。
MAX_THINKING_TOKENS=0 で Anthropic 固有の thinking 機能を無効化しています。
遭遇した 4 つのエラーと対処法
検証過程で遭遇したエラーを、発生順に紹介します。
合計で 2〜3 時間ほど費やしました。
エラー 1: モデル名不一致(400 Bad Request)
症状: Claude Code が送信するモデル名が config.yaml の定義と一致せず 400 エラー。
原因: Claude Code が実際に送信するモデル名は、CLI のバージョンや設定によって変わることがあります。
対処: LiteLLM のログ(docker compose logs -f)から実際のモデル名を確認し、config.yaml を修正しました。
最初にこの原因を特定するだけで 30 分ほどかかりました。
LiteLLM のログを有効にしておくのが鉄則です。
エラー 2: “does not support thinking”(500 Internal Server Error)
症状: thinking パラメータがサポートされていないというエラー。
原因: Qwen 3 が Anthropic の thinking パラメータを理解できません。
対処: MAX_THINKING_TOKENS=0 環境変数で Claude Code 側から thinking を無効化しました。
加えて、LiteLLM の additional_drop_params にも thinking と thinking_budget_tokens を指定して二重に対策しています。
エラー 3: “Operation not allowed” レスポンス
症状: LLM からの応答が Operation not allowed というテキスト。
HTTP レベルではエラーではなく、正常なレスポンスとして返ってきます。
原因: Qwen 3 が Claude Code のシステムプロンプトを読み、その中のセキュリティ制約を「自分への指示」と誤認して動作を拒否していました。
Claude Code のシステムプロンプトには、ファイル操作やコマンド実行に関する詳細な権限制御が含まれています。
Qwen 3 はこれを「やってはいけないこと」と解釈してしまったようです。
対処: これはモデルの指示追従能力の問題であり、設定レベルでは回避できませんでした。
エラー 4: JSON 形式の応答
症状: {"response": "4"} のような JSON 形式で応答が返る。
原因: Claude Code のシステムプロンプトに含まれる出力フォーマット指示に、Qwen 3 が過剰に従っていました。
本来はツール呼び出しの応答形式ですが、通常の会話応答まで JSON で返してしまいます。
対処: これもモデル側の問題であり、設定では回避できませんでした。
なぜ動かなかったのか: 根本原因の分析
4 つのエラーのうち、最初の 2 つは設定で回避できました。
しかし後半の 2 つ——システムプロンプトの誤解釈と JSON 応答——はモデルの能力に起因する問題です。
Claude Code のシステムプロンプトは非常に複雑で、以下の要素を含みます。
- ファイル操作・コマンド実行の権限制御
- ツール呼び出しの応答フォーマット指定
- セキュリティ制約と禁止事項
- コンテキスト管理のルール
これらを正確に解釈して、適切に応答するには、高度な指示追従能力が必要です。
Qwen 3 系モデルは汎用的な性能は高いのですが、Claude Code が求めるレベルの指示追従には達していませんでした。
得られた知見
検証は「失敗」でしたが、以下の知見は今後のローカル LLM 活用に役立ちます。
- LiteLLM の
drop_params は強力: プロバイダ固有のパラメータを自動除去でき、異なる API 間の橋渡しに使えます
- Ollama + Docker Compose の組み合わせは安定: 環境構築自体は
config.yaml 1 ファイルで完結します。LLM プロキシとしての基盤は実用レベルです
- システムプロンプトの複雑さがボトルネック: AI エージェントツールをローカル LLM で動かす際の最大の壁は、モデルの基本性能ではなく、システムプロンプトへの追従能力でした
claude --qwen のようなフラグ切り替え: シェル関数での環境変数切り替えは、他のツールでも応用できるパターンです
よくある質問
Q: 他のローカル LLM なら動きますか?
Qwen 3 で動かなかった主因は指示追従能力です。
Llama 3.3 70B や DeepSeek Coder V2 など、より大きなパラメータ数のモデルであれば改善する可能性はあります。
ただし、Claude Code のシステムプロンプトの複雑さを考えると、現時点では厳しいかもしれません。
Q: LiteLLM の設定は難しいですか?
Docker と Ollama がインストール済みであれば、config.yaml を書くだけなので比較的簡単です。
つまづきやすいのはモデル名のマッピングで、LiteLLM のログを見ながら調整する必要があります。
Q: コスト削減の他の方法はありますか?
Claude Code には --model オプションで軽量モデルを指定する方法があります。
また、Anthropic の API キャッシュ機能を活用すれば、同じプロンプトの再送信コストを削減できます。
完全にローカルで動かすよりも、まずはこちらの方が現実的です。
まとめ
Claude Code を LiteLLM + Ollama + Qwen 3 でローカル動作させる検証を行いましたが、システムプロンプトの互換性が壁となり実用には至りませんでした。
- 環境構築自体は簡単: Docker Compose +
config.yaml で LiteLLM プロキシが立ち上がります
- 設定で回避できるエラーと、できないエラーがある:
drop_params で Anthropic 固有パラメータは除去できますが、モデルの指示追従能力は設定では補えません
- AI エージェントのローカル LLM 化は「次の段階」: モデル性能の向上と、エージェントツール側のプロキシ対応が進めば、実現の可能性は高まります
「失敗した検証」ですが、LiteLLM の活用パターンや Ollama との連携方法など、他のプロジェクトでも再利用できる知見が得られました。
ローカル LLM の進化は速いので、半年後には状況が変わっているかもしれません。